The Silver Chair is a sequel to The Voyage of the Dawn Treader and the fourth book of the
Chronicles of Narnia in original publication order. (For more about
publication order, see the introduction to my review of
The Lion, the Witch and the Wardrobe.)
Apart from a few references to The Voyage of the Dawn Treader at
the start, it stands sufficiently on its own that you could read it
without reading the other books, although I have no idea why you'd want
to.
We have finally arrived at my least favorite of the Narnia books and the
one that I sometimes skipped during re-reads. (One of my objections to
the new publication order is that it puts The Silver Chair and
The Last Battle back-to-back, and I don't think you should do that
to yourself as a reader.) I was hoping that there would be previously
unnoticed depth to this book that would redeem it as an adult reader.
Sadly, no; with one very notable exception, it's just not very good.
MAJOR SPOILERS BELOW.
The Silver Chair opens on the grounds of the awful school to which
Eustace's parents sent him: Experiment House. That means it opens (and
closes) with a more extended version of Lewis's rant about schools. I
won't get into this in detail since it's mostly a framing device, but
Lewis is remarkably vicious and petty. His snide contempt for putting
girls and boys in the same school did not age well, nor did his emphasis
at the end of the book that the incompetent head of the school is a woman.
I also raised an eyebrow at holding up ordinary British schools as a model
of preventing bullying.
Thankfully, as Lewis says at the start, this is not a school story. This
is prelude to Jill meeting Eustace and the two of them escaping the
bullies via a magical door into Narnia. Unfortunately, that's the second
place The Silver Chair gets off on the wrong foot.
Jill and Eustace end up in what the reader of the series will recognize as
Aslan's country and almost walk off the vast cliff at the end of the
world, last seen from the bottom in The Voyage of the Dawn Treader.
Eustace freaks out, Jill (who has a much better head for heights) goes
intentionally close to the cliff in a momentary impulse of arrogance
before realizing how high it is, Eustace tries to pull her back, and
somehow Eustace falls over the edge.
I do not have a good head for heights, and I wonder how much of it is due
to this memorable scene. I certainly blame Lewis for my belief that
pulling someone else back from the edge of a cliff can result in you being
pushed off, something that on adult reflection makes very little sense but
which is seared into my lizard brain. But worse, this sets the tone for
the rest of the story: everything is constantly going wrong because
Eustace and Jill either have normal human failings that are
disproportionately punished or don't successfully follow esoteric and
unreasonably opaque instructions from Aslan.
Eustace is safe, of course; Aslan blows him to Narnia and then gives Jill
instructions before sending her afterwards. (I suspect the whole business
with the cliff was an authorial cheat to set up Jill's interaction with
Aslan without Eustace there to explain anything.) She and Eustace have
been summoned to Narnia to find the lost Prince, and she has to memorize
four Signs that will lead her on the right path.
Gah, the Signs. If you were the sort of kid that I was, you immediately
went back and re-read the Signs several times to memorize them like Jill
was told to. The rest of this book was then an exercise in anxious
frustration. First, Eustace is an ass to Jill and refuses to even listen
to the first Sign. They kind of follow the second but only with heavy
foreshadowing that Jill isn't memorizing the Signs every day like she's
supposed to. They mostly botch the third and have to backtrack to follow
it. Meanwhile, the narrator is constantly reminding you that the kids
(and Jill in particular) are screwing up their instructions. On
re-reading, it's clear they're not doing that poorly given how obscure the
Signs are, but the ominous foreshadowing is enough to leave a reader a
nervous wreck.
Worse, Eustace and Jill are just miserable to each other through the whole
book. They constantly bicker and snipe, Eustace doesn't want to listen to
her and blames her for everything, and the hard traveling makes it all
worse. Lewis does know how to tell a satisfying redemption arc; one of
the things I have always liked about Edmund's story is that he learns his
lesson and becomes my favorite character in the subsequent stories. But,
sadly, Eustace's redemption arc is another matter. He's totally different
here than he was at the start of The Voyage of the Dawn Treader (to
the degree that if he didn't have the same name in both books, I wouldn't
recognize him as the same person), but rather than a better person he
seems to have become a different sort of ass. There's no sign here of the
humility and appreciation for friendship that he supposedly learned from
his time as a dragon.
On top of that, the story isn't very interesting. Rilian, the lost
Prince, is a damp squib who talks in the irritating archaic accent that
Lewis insists on using for all Narnian royalty. His story feels like
Lewis lifted it from medieval Arthurian literature; most of it could be
dropped into a collection of stories of knights of the Round Table without
seeming out of place. When you have a country full of talking animals and
weirdly fascinating bits of theology, it's disappointing to get a
garden-variety story about an evil enchantress in which everyone is noble
and tragic and extremely stupid.
Thankfully, The Silver Chair has one important redeeming quality:
Puddleglum.
Puddleglum is a Marsh-wiggle, a bipedal amphibious sort who lives alone in
the northern marshes. He's recruited by the owls to help the kids with
their mission when they fail to get King Caspian's help after blowing the
first Sign. Puddleglum is an absolute delight: endlessly pessimistic,
certain the worst possible thing will happen at any moment, but also
weirdly cheerful about it. I love Eeyore characters in general, but
Puddleglum is even better because he gives the kids' endless bickering
exactly the respect that it deserves.
"But we all need to be very careful about our tempers, seeing all the
hard times we shall have to go through together. Won't do to quarrel,
you know. At any rate, don't begin it too soon. I know these
expeditions usually end that way; knifing one another, I
shouldn't wonder, before all's done. But the longer we can keep off
it "
It's even more obvious on re-reading that Puddleglum is the only effective
member of the party. Jill has only a couple of moments where she gets the
three of them past some obstacle. Eustace is completely useless; I can't
remember a single helpful thing he does in the entire book. Puddleglum
and his pessimistic determination, on the other hand, is right about
nearly everything at each step. And he's the one who takes decisive
action to break the Lady of the Green Kirtle's spell near the end.
I was expecting a bit of sexism and (mostly in upcoming books) racism when
re-reading these books as an adult given when they were written and who
Lewis was, but what has caught me by surprise is the colonialism. Lewis
is weirdly insistent on importing humans from England to fill all the
important roles in stories, even stories that are entirely about Narnians.
I know this is the inherent weakness of portal fantasy, but it bothers me
how little Lewis believes in Narnians solving their own problems.
The Silver Chair makes this blatantly obvious: if Aslan had just
told Puddleglum the same information he told Jill and sent a Badger or a
Beaver or a Mouse along with him, all the evidence in the book says the
whole affair would have been sorted out with much less fuss and anxiety.
Jill and Eustace are far more of a hindrance than a help, which makes for
frustrating reading when they're supposedly the protagonists.
The best part of this book is the underground bits, once they finally get
through the first three Signs and stumble into the Lady's kingdom far
below the surface. Rilian is a great disappointment, but the fight
against the Lady's mind-altering magic leads to one of the great quotes of
the series, on par with Reepicheep's speech in The Voyage of the
Dawn Treader.
"Suppose we have only dreamed, or made up, all those things
trees and grass and sun and moon and stars and Aslan himself. Suppose
we have. Then all I can say is that, in that case, the made-up things
seem a good deal more important than the real ones. Suppose this
black pit of a kingdom of yours is the only world. Well, it
strikes me as a pretty poor one. And that's a funny thing, when you
come to think of it. We're just babies making up a game, if you're
right. But four babies playing a game can make a play-world which
licks your real world hollow. That's why I'm going to stand by the
play world. I'm on Aslan's side even if there isn't any Aslan to lead
it. I'm going to live as like a Narnian as I can even if there isn't
any Narnia. So, thanking you kindly for our supper, if these two
gentlemen and the young lady are ready, we're leaving your court at
once and setting out in the dark to spend our lives looking for
Overland. Not that our lives will be very long, I should think; but
that's small loss if the world's as dull a place as you say."
This is Puddleglum, of course. And yes, I know that this is apologetics
and Lewis is talking about Christianity and making the case for faith
without proof, but put that aside for the moment, because this is still
powerful life philosophy. It's a cynic's litany against cynicism. It's a
pessimist's defense of hope.
Suppose we have only dreamed all those things like justice and fairness
and equality, community and consensus and collaboration, universal basic
income and effective environmentalism. The dreary magic of the realists
and the pragmatists say that such things are baby's games, silly
fantasies. But you can still choose to live like you believe in them. In
Alasdair Gray's reworking of a line from Dennis Lee, "work as if you live
in the early days of a better nation."
That's one moment that I'll always remember from this book. The other is
after they kill the Lady of the Green Kirtle and her magic starts to fade,
they have to escape from the underground caverns while surrounded by the
Earthmen who served her and who they believe are hostile. It's a tense
moment that turns into a delightful celebration when they realize that the
Earthmen were just as much prisoners as the Prince was. They were forced
from a far deeper land below, full of living metals and salamanders who
speak from rivers of fire. It's the one moment in this book that I
thought captured the magical strangeness of Narnia, that sense that there
are wonderful things just out of sight that don't follow the normal
patterns of medieval-ish fantasy.
Other than a few great lines from Puddleglum and some moments in Aslan's
country, the first 60% of this book is a loss and remarkably frustrating
to read. The last 40% isn't bad, although I wish Rilian had any
discernible character other than generic Arthurian knight. I don't know
what Eustace is doing in this book at all other than providing a way for
Jill to get into Narnia, and I wish Lewis had realized Puddleglum could be
the protagonist. But as frustrating as The Silver Chair can be, I
am still glad I re-read it. Puddleglum is one of the truly memorable
characters of children's literature, and it's a shame he's buried in a
weak mid-series book.
Followed, in the original publication order, by The Horse and His
Boy.
Rating: 6 out of 10
Ten years ago I began
the olduse.net exhibit,
spooling out Usenet history in real time with a 30 year delay.
My archive has reached its end, and ten years is
more than long enough to keep running something you cobbled together
overnight way back when. So, this is the end for olduse.net.
The site will continue running for another week or so, to give you time to
read the last posts. Find the very last one, if you can!
The source code used to run it, and the content of the website have
themselves been archived up for posterity at
The Internet Archive.
Sometime in 2022, a spammer will purchase the domain, but not find it to be
of much value.
The Utzoo archives that underlay it have currently sadly
been censored off the Internet
by someone. This will be unsuccessful; by now they have spread and many
copies will live on.
I told a lie ten years ago.
You can post to olduse.net, but it won't show up for at least 30 years.
Actually, those posts drop right now! Here are the followups
to 30-year-old Usenet posts that I've accumulated over the past decade.
Mike replied in 2011 to JPM's post in 1981 on fa.arms-d
"Re: CBS Reports"
A greeting from the future:
I actually watched this yesterday (2011-06-10) after reading about it here.
Christian Brandt replied in 2011 to schrieb phyllis's post in 1981 on the "comments" newsgroup
"Re: thank you rrg"
Funny, it will be four years until you post the first subnet post i
ever read and another eight years until my own first subnet post shows up.
i suggest that darth vader is luke skywalker's mother.
You may be on to something there.
Martijn Dekker replied in 2012 to henry's post in 1982 on the "test" newsgroup
"Re: another boring test message"
trentbuck replied in 2012 to dwl's post in 1982 on the "net.jokes" newsgroup
"Re: A child hood poem"
Eveline replied in 2013 to a post in 1983 on net.jokes.q
"Re: A couple"
Ha!
Bill Leary replied in 2015 to Darin Johnson's post in 1985 on net.games.frp
"Re: frp & artwork"
Frederick Smith replied in 2021 to David Hoopes's post in 1990 on trial.rec.metalworking
"Re: Is this group still active?"
The Great Electric Airplane Race
It took me quite sometime to write as have been depressed about things. Then a few days back saw Nova s The Great Electric Airplane Race. While it was fabulous and a pleasure to see and know that there are more than 200 odd startups who are in the race of making an electric airplane which works and has FAA certification. I was disappointed though that there no coverage of any University projects.
From what little I know, almost all advanced materials which U.S. had made has been first researched in mostly Universities and when it is close to fruition then either spin-off as a startup or give to some commercial organization/venture to make it scalable and profitable. If they had, I am sure more people could be convinced to join sciences and engineering in college. I actually do want to come to this as part of both general medicine and vaccine development in U.S. but will come later. The idea that industry works alone should be discouraged, but that perhaps may require another article to articulate why I believe so.
Medical Device Ventilators in India
Before the pandemic, probably most didn t know what a ventilator is and was, at least I didn t, although I probably used it during my somewhat brief hospital stay a couple of years ago. It entered into the Indian twitter lexicon more so in the second wave as the number of people who got infected became more and more and the ventilators which were serving them became less and less just due to sheer mismatch of numbers and requirements.
Rich countries donated/gifted ventilators to India on which GOI put GST of 28%. Apparently, they are a luxury item, just like my hearing aid.
Last week Delhi High Court passed a judgement that imposition of GST should not be on a gift like ventilators or oxygenators. The order can be found here. Even without reading the judgement the shout from the right was judicial activism while after reading it is a good judgement which touches on several points. The first, in itself, stating the dichotomy that if a commercial organization wanted to import a ventilator or an oxygenator the IGST payable is nil while for an individual it is 12%. The State (here State refers to State Government in this case Gujarat Govt.) did reduce the IGST for state from 12% to NIL IGST for federal states but that to till only 30.06.2021. No relief to individuals on that account.
The Court also made use of Mr. Arvind Datar, as Amicus Curiae or friend of court. The petitioner, an 85-year-old gentleman who has put it up has put broad assertions under Article 21 (right to live) and the court in its wisdom also added Article 14 which enshrines equality of everyone before law.
The Amicus Curiae, as his duty, guided the court into how the IGST law works and shared a brief history of the law and the changes happening before and after it. During his submissions, he also shared the Mega Exemption Notification no. 50/2017 under which several items are there which are exempted from putting IGST. The Amicus Curiae did note that such exemptions were also there before Mega Exemption Notification had come into play.
However, DGFT (Directorate General of Foreign Trade) on 30-04-2021 issued notification No. 4/2015-2020 through which oxygenators had been exempted from Custom Duty/BCD (Basic Customs Duty. In another notification on no. 30/2021 dated 01.05.2021 it reduced IGST from 28% to 12% for personal use. If however the oxygenator was procured by a canalizing agency (bodies such as State Trading Corporation of India (STC) or/and Metals and Minerals Corporation (MMTC) and such are defined as canalising agents) then it will be fully exempted from paying any sort of IGST, albeit subject to certain conditions. What the conditions are were not shared in the open court.
The Amicus Curiae further observed that it is contrary to practice where both BCD and IGST has been exempted for canalising agents and others, some IGST has to be paid for personal use. To share within the narrow boundaries of the topic, he shared entry no. 607A of General Exemption no.190 where duty and IGST in case of life-saving drugs are zero provided the life-saving drugs imported have been provided by zero cost from an overseas supplier for personal use.
He further shared that the oxygen generator would fall in the same entry of 607A as it fulfills all the criteria as shared for life-saving medicines and devices. He also used the help of Drugs and Cosmetics Act 1940 which provides such a relief.
The Amicus Curiae further noted that GOI amended its foreign trade policy (2015-2020) via notification no.4/2015-2020, dated 30.04.2021, issued by DGFT where Rakhi and life-saving drugs for personal use has been exempted from BCD till 30-07-2021. No reason not to give the same exemption to oxygenators which fulfill the same thing.
The Amicus Curiae, further observes that there are exceptional circumstances provisions as adverted to in sub-section (2) of Section 25 of the Customs Act, whereby Covid-19 which is known and labelled as a pandemic where the distinctions between the two classes of individuals or agencies do not make any sense. While he did make the observation that exemption from duty is not a right, in the light of the pandemic and Article 14, it does not make sense to have distinctions between the two classes of importers.
He further shared from Circular no. 9/2014-Customs, dated 19.08.2014 by CBEC (Central Board of Excise and Customs) which gave broad exemptions under Section 25 (2) of the same act in respect of goods and services imported for safety and rehabilitation of people suffering and effected by natural disasters and epidemics.
He further submits that the impugned notification is irrational as there is no intelligible differentia rule applied or observed in classifying the import of oxygen concentrators into two categories. One, by the State and its agencies; and the other, by an individual for personal use by way of gift. So there was an absence of adequate determining principle . To bolster his argument, he shared the judgements of
a) Union of India vs. N.S. Rathnam & Sons, (2015) 10 SCC 681 (N.S. Ratnams and Sons Case)
b) Shayara Bano vs. Union of India, (2017) 9 SCC 1 (Shayara Bano Case)
The Amicus Curiae also rightly observed that the right to life also encompasses within it, the right to health. You cannot have one without the other and within that is the right to have affordable treatment. He further stated that the state does not only have a duty but a positive obligation is cast upon it to ensure that the citizen s health is secured. He again cited Navtej Singh Johars vs Union of India (Navtej Singh Johar Case) in defence of right to life. Mr. Datar also shared that unlike in normal circumstances, it is and should be enough to show distinct and noticeable burdensomeness which is directly attributable to the impugned/questionable tax. The gentleman cited Indian Express Newspapers (Bombay) Private Limited vs. Union of India, (1985) 1 SCC 641 (Indian Express case) 1985 which shared both about Article 19 (1) (a) and Article 21.
Bloggers note At this juncture, I should point out which I am sharing the judgement and I would be sharing only the Amicus Curiae POV and then the judge s final observations. While I was reading it, I was stuck by the fact that the Amicus Curiae had cited 4 cases till now, 3 of them are pretty well known both in the legal fraternity and even among public at large. Another 3 which have been shared below which are also of great significance. Hence, felt the need to share the whole judgement.
The Amicus Curiae further observed that this tax would have to be disproportionately will have to be paid by the old and the infirm, and they might find it difficult to pay the amounts needed to pay the customs duty/IGST as well as find the agent to pay in this pandemic.
Blogger Note The situation with the elderly is something like this. Now there are a few things to note, only Central Govt. employees and pensioners get pensions which has been freezed since last year. The rest of the elderly population does not. The rate of interest has fallen to record lows from 5-6% in savings interest rate to 2% and on Fixed Deposits at 4.9% while the nominal inflation rate has up by 6% while CPI and real inflation rates are and would be much more. And this is when there is absolutely no demand in the economy. To add to all this, RBI shared a couple of months ago that fraud of 5 trillion rupees has been committed between 2015 and 2019 in banks. And this is different from the number of record NPA s that have been both in Public and Private Sector banks. To get out of this, the banks have squeezed their customers and are squeezing as well as asking GOI for bailouts. How much GOI is responsible for the frauds as well as NPA s would probably require its own space. And even now, RBI and banks have made heavy provisions as lockdowns are still a facet and are supposed to remain a facet till the end of the year or even next year (all depending upon when we get the vaccine).
The Amicus Curiae further argued that the ventilators which are available locally are of bad quality. The result of all this has resulted in a huge amount of unsurmountable pressure on hospitals which they are unable to overcome. Therefore, the levy of IGST on oxygenators has direct impact on health of the citizen. So the examination of the law should not be by what intention it was but how it is affecting citizen rights now. For this he shared R.C.Cooper vs Union of India (another famous case R.C. Cooper vs Union of India) especially paragraph 49 and Federation of Hotel & Restaurant Association of India vs. Union of India, (1989) at paragraph 46 (Federation of Hotel Case)
Mr. Datar further shared the Supreme Court order dated 18.12.2020, passed in Suo Moto Writ Petition(Civil) No.7/2020, to buttress the plea that the right to health includes the right to affordable treatment.
Blogger s Note For those, who don t know Suo Moto is when the Court, whether Supreme Court or the High Courts take up a matter for public good. It could be in anything, law and order, Banking, Finance, Public Health etc. etc. This was the norm before 2014. The excesses of the executive were curtailed by both the Higher and the lower Judiciary. That is and was the reason that Judiciary is and was known as the third pillar of Indian democracy. A good characterization of Suo Moto can be found here.
Before ending his submission, the learned Amicus Curiae also shared Jeeja Ghosh vs. Union of India, (2016) (Jeeja Ghosh Case, an outstanding case as it deals with people with disabilities and their rights and the observations made by the Division Bench of Hon ble Mr. Justice A. K. Sikri as well as Hon ble Mr. Justice R. K. Agrawal.)
After Amicus Curiae completed his submissions, it was the turn of Mr. Sudhir Nandrajog, and he adopted the arguments and submissions made by the Amicus Curiae. The gentleman reiterated the facts of the case and how the impugned notification was violative of both Article 14 and 21 of the Indian Constitution.
Blogger s Note The High Court s judgement which shows all the above arguments by the Amicus Curiae and the petitioner s lawyer also shared the State s view. It is only on page 24, where the Delhi High Court starts to share its own observations on the arguments of both sides.
Judgement continued The first observation that the Court makes is that while the petitioner demonstrated that the impugned tax imposition would have a distinct and noticeable burdensomeness while the State did not state or share in any way how much of a loss it would incur if such a tax were let go and how much additional work would have to be done in order to receive this specific tax. It didn t need to do something which is down the wire or mathematically precise, but it didn t even care to show even theoretically how many people will be affected by the above. The counter-affidavit by the State is silent on the whole issue.
The Court also contended that the State failed to prove how collecting IGST from the concerned individuals would help in fighting coronavirus in any substantial manner for the public at large. The High Court shared observations from the Navtej Singh Johar case where it is observed that the State has both negative and positive obligations to ensure that its citizens are able to enjoy the right to health.
The High Court further made the point that no respectable person does like to be turned into a charity case. If the State contends that those who obey the law should pay the taxes then it is also obligatory on the state s part to lessen exactions such as taxes at the very least in times of war, famine, floods, epidemics and pandemics. Such an approach would lead a person to live a life of dignity which is part of Article 21 of the Constitution.
Another point that was made by the State that only the GST council is able to make any changes as regards to exemptions rather than the State were found to be false as the State had made some exemptions without going to the GST council using its own powers under Section 25 of the Customs Act.
The Court also points out that it does send a discriminatory pattern when somebody like petitioner has to pay the tax for personal use while those who are buying it for commercial use do not have to pay the tax.
The Court agreed of the view of the Amicus Curiae, Mr. Datar that oxygenator should be taxed at NIL rate at IGST as it is part of life-saving drugs and oxygenator fits the bill as medical equipment as it is used in the treatment, mitigation and prevention of spread of Coronavirus. Mr. Datar also did show that oxygenator is placed at the same level as other life-saving drugs. The Court felt further emboldened as the observations by Supreme Court in State of Andhra Pradesh vs. Linde India Limited, 2020 ( State of Andhra Pradesh vs Linde Ltd.)
The Court further shared many subsequent notifications from the State and various press releases by the State itself which does make the Court s point that oxygenators indeed are drugs as defined in the court case above. The State should have it as part of notification 190. This would preserve the start of the notification date from 03.05.2021 and the state would not have to issue a new notification.
The Court further went to postulate that any persons similar to the petitioner could avail of the same, if they furnish a letter of undertaking to an officer designated by the State that the medical equipment would not be put to commercial use. Till the state does not do that, in the interim the importer could give the same undertaking to Joint Secretary, Customs or their nominee can hand over the same to custom officer.
The Court also shared that it does not disagree with the State s arguments but the challenges which have arisen are in a unique time period/circumstances, so they are basing their judgement based on how the situation is.
The Court also mentioned an order given by Supreme Court Diary No. 10669/2020 passed on 20.03.2020 where SC has taken pains to understand the issues faced by the citizens. The court also mentioned the Small Scale Industrial Manufactures Association Case (both of these cases I don t know) .
So in conclusion, the Court holds the imposition of IGST on oxygenator which are imported by individuals as gifts from their relatives as unconstitutional. They also shared that any taxes taken by GOI in above scenario have to be returned. The relief to the state is they will not have to pay interest cost on the same.
To check misuse of the same, the petitioner or people who are in similar circumstances would have to give a letter of undertaking to an officer designated by the State within 7 days of the state notifying the patient or anybody authorized by him/her to act on their behalf to share the letter of undertaking with the State. And till the State doesn t provide an officer, the above will continue.
Hence, both the writ petition and the pending application are disposed off.
The Registry is directed to release any money deposited by the petitioner along with any interest occurred on it (if any) .
At the end they record appreciation of Mr. Arvind Datar, Mr. Zoheb Hossain, Mr. Sudhir Nandrajog as well as Mr. Siddharth Bambha. It is only due to their assistance that the court could reach the conclusion it did.
For Delhi High Court
RAJIV SHAKDHER, J.
TALWANT SINGH, J.
May 21, 2020
Blogger s Observations Now, after the verdict GOI does have few choices, either accept the verdict or appeal in the SC. A third choice is to make a committee and come to the same conclusions via the committee. GOI has done something similar in the past. If that happens and the same conclusions are reached as before, then the aggrieved may have no choice but to appear in the highest court of law. And this will put the aggrieved at a much more vulnerable place than before as SC court fees, lawyer fees etc. are quite high compared to High Courts. So, there is a possibility that the petitioner may not even approach unless and until some non-profit (NGO) does decide to fight and put it up as common cause or something similar.
There is another judgement that I will share, probably tomorrow. Thankfully, that one is pretty short compared to this one. So it should be far more easier to read. FWIW, I did learn about the whole freeenode stuff and many channels who have shifted from freenode to libera. I will share my own experience of the same but that probably will take a day or two.
Zeeshan of IYC (India Youth Congress) along with Salman Khan s non-profit Being Human getting oxygenators
The above picture of Zeeshan. There have been a whole team of Indian Youth Congress workers (main opposition party to the ruling party) who have doing lot of relief effort. They have been buying Oxygenators from abroad with help of Being Human Foundation started by Salman Khan, an actor who works in A-grade movies in Bollywood.
There are many resources for network automation with Ansible. Most
of them only expose the first steps or limit themselves to a
narrow scope. They give no clue on how to expand from that. Real
network environments may be large, versatile, heterogeneous, and filled
with exceptions. The lack of real-world examples for Ansible
deployments, unlike Puppet and SaltStack, leads many teams to
build brittle and incomplete automation solutions.
We have released under an open-source license our attempt
to tackle this problem:
Jerikan, a tool to build configuration files from a single
source of truth and Jinja2 templates, along with its
integration into the GitLab CI system;
an Ansible playbook to deploy these configuration files on
network devices; and
the configuration data and the templates for our, now defunct,
datacenters in San Francisco and South Korea, covering many vendors
(Facebook Wedge 100, Dell S4048 and S6010, Juniper QFX 5110,
Juniper QFX 10002, Cisco ASR 9001, Cisco Catalyst 2960, Opengear
console servers, and Linux), and many functionalities
(provisioning, BGP-to-the-host routing, edge routing, out-of-band
network, DNS configuration, integration with NetBox and IRRs).
Here is a quick demo to configure a new peering:
This work is the collective effort of C dric Hasco t,
Jean-Christophe Legatte, Lo c Pailhas, S bastien Hurtel,
Tchadel Icard, and Vincent Bernat. We are the network team of
Blade, a French company operating Shadow, a cloud-computing
product. In May 2021, our company was bought by Octave Klaba and
the infrastructure is being transferred to OVHcloud, saving
Shadow as a product, but making our team redundant.
Our network was around 800 devices, spanning over 10 datacenters with
more than 2.5 Tbps of available egress bandwidth. The released
material is therefore a substantial example of managing a medium-scale
network using Ansible. We have left out the handling of our legacy
datacenters to make the final result more readable while keeping
enough material to not turn it into a trivial example.
Jerikan
The first component is Jerikan. As input, it takes a list of
devices, configuration data, templates, and validation scripts. It
generates a set of configuration files for each device. Ansible
could cover this task, but it has the following limitations:
Jerikan inputs and outputs
If you want to follow the examples, you only need to have Docker and
Docker Compose installed. Clone the repository and you
are ready!
Source of truth
We use YAML files, versioned with Git, as the single source of
truth instead of using a database, like NetBox, or a mix of a
database and text files. This provides many advantages:
anyone can use their preferred text editor;
the team prepares changes in branches;
the team reviews changes using merge requests;
the merge requests expose the changes to the generated configuration files;
rollback to a previous state is easy; and
it is fast.
The first file is devices.yaml. It contains the
device list. The second file is classifier.yaml.
It defines a scope for each device. A scope is a set of keys and
values. It is used in templates and to look up data associated with a
device.
The device name is matched against a list of regular expressions and
the scope is extended by the result of each match. For
to1-p1.sk1.blade-group.net, the following subset of
classifier.yaml defines its scope:
The third file is searchpaths.py. It describes
which directories to search for a variable. A Python function provides
a list of paths to look up in data/ for a given scope. Here
is a simplified version:2
Variables are scoped using a namespace that should be specified when
doing a lookup. We use the following ones:
system for accounts, DNS, syslog servers,
topology for ports, interfaces, IP addresses, subnets,
bgp for BGP configuration
build for templates and validation scripts
apps for application variables
When looking up for a variable in a given namespace, Jerikan looks
for a YAML file named after the namespace in each directory in the
search paths. For example, if we look up a variable for
to1-p1.sk1.blade-group.net in the bgp namespace, the following
YAML files are processed: host/sk1/to1-p1/bgp.yaml,
location/sk1/bgp.yaml, os/cumulus-dell-s4048/bgp.yaml,
os/cumulus/bgp.yaml, and common/bgp.yaml. The search stops at the
first match.
The schema.yaml file allows us to override this
behavior by asking to merge dictionaries and arrays across all
matching files. Here is an excerpt of this file for the topology
namespace:
The last feature of the source of truth is the ability to use Jinja2
templates for keys and values by prefixing them with ~ :
# In data/os/junos/system.yamlnetbox:manufacturer:Junipermodel:"~ model upper "# In data/groups/tor-bgp-compute/system.yamlnetbox:role:net_tor_gpu_switch
Looking up for netbox in the system namespace for
to1-p2.ussfo03.blade-group.net yields the following result:
# In groups/adm-gateway/topology.yamlinterface-rescue:address:"~ lookup('topology','addresses').rescue "up:-"~iprouteadddefaultvialookup('topology','addresses').rescue ipaddr('first_usable')tablerescue"-"~ipruleaddfromlookup('topology','addresses').rescue ipaddr('address')tablerescuepriority10"# In groups/adm-gateway-sk1/topology.yamlinterfaces:ens1f0:"~ lookup('topology','interface-rescue') "
This yields the following result:
$ ./run-jerikan lookup gateway1.sk1.blade-group.net topology interfaces
[ ]ens1f0: address: 121.78.242.10/29 up: - ip route add default via 121.78.242.9 table rescue - ip rule add from 121.78.242.10 table rescue priority 10
When putting data in the source of truth, we use the following rules:
Don t repeat yourself.
Put the data in the most specific place without breaking the first rule.
Use templates with parsimony, mostly to help with the previous rules.
Restrict the data model to what is needed for your use case.
The first rule is important. For example, when specifying IP addresses
for a point-to-point link, only specify one side and deduce the other
value in the templates. The last rule means you do not need to mimic a
BGP YANG model to specify BGP peers and policies:
Templates are using Jinja2. This is the same engine used in
Ansible. Jerikan ships some custom filters but also reuse some of
the useful filters from Ansible, notably
ipaddr. Here is an excerpt of
templates/junos/base.j2 to configure DNS
and NTP servers on Juniper devices:
system ntp %forntpinlookup("system","ntp")% server ntp; %endfor% name-server %fordnsinlookup("system","dns")% dns; %endfor%
devices() returns the list of devices matching a set of
conditions on the scope. For example, devices("location==ussfo03",
"groups==tor-bgp") returns the list of devices in San Francisco in
the tor-bgp group. You can also omit the operator if you want the
specified value to be equal to the one in the local scope. For
example, devices("location") returns devices in the current
location.
lookup() does a key lookup. It takes the namespace, the key, and
optionally, a device name. If not provided, the current device
is assumed.
scope() returns the scope of the provided device.
Here is how you would define iBGP sessions between edge devices in the
same location:
%forneighborindevices("location","groups==edge")ifneighbor!=device% %foraddressinlookup("topology","addresses",neighbor).loopbacktolist% protocols bgp group IPVaddressipv-EDGES-IBGP neighbor address description "IPvaddressipv: iBGP to neighbor"; %endfor% %endfor%
We also have a global key-value store to save information to be
reused in another template or device. This is quite useful to
automatically build DNS records. First, capture the IP address
inserted into a template with store() as a filter:
Templates are compiled locally with ./run-jerikan build. The
--limit argument restricts the devices to generate configuration
files for. Build is not done in parallel because a template may depend
on the data collected by another template. Currently, it takes 1
minute to compile around 3000 files spanning over 800 devices.
Output of Jerikan after building configuration files for six devices
When an error occurs, a detailed traceback is displayed, including the
template name, the line number and the value of all visible variables.
This is a major time-saver compared to Ansible!
templates/opengear/config.j2:15: in top-level template code
config.interfaces. interface .netmask adddress ipaddr("netmask")
continent = 'us'
device = 'con1-ag2.ussfo03.blade-group.net'
environment = 'prod'
host = 'con1-ag2.ussfo03'
infos = 'address': '172.30.24.19/21'
interface = 'wan'
location = 'ussfo03'
loop = <LoopContext 1/2>
member = '2'
model = 'cm7132-2-dac'
os = 'opengear'
shorthost = 'con1-ag2'
_ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _ _
value = JerkianUndefined, query = 'netmask', version = False, alias = 'ipaddr'
[ ]
# Check if value is a list and parse each element
if isinstance(value, (list, tuple, types.GeneratorType)):
_ret = [ipaddr(element, str(query), version) for element in value]
return [item for item in _ret if item]
> elif not value or value is True:
E jinja2.exceptions.UndefinedError: 'dict object' has no attribute 'adddress'
We don t have general-purpose rules when writing templates. Like for
the source of truth, there is no need to create generic templates able
to produce any BGP configuration. There is a balance to be found
between readability and avoiding duplication. Templates can become
scary and complex: sometimes, it s better to write a filter or a
function in jerikan/jinja.py. Mastering
Jinja2 is a good investment. Take time to browse through our
templates as some of them show interesting features.
Checks
Optionally, each configuration file can be validated by a script in
the checks/ directory. Jerikan looks up the key checks
in the build namespace to know which checks to run:
In the above example, checks/junoser is executed if there is a
change to the generated config.txt file. It also outputs a
transformed version of the configuration file which is easier to
understand when using diff. Junoser checks a Junos configuration
file using Juniper s XML schema definition for Netconf.5 On
error, Jerikan displays:
jerikan/build.py:127: RuntimeError
-------------- Captured syntax check with Junoser call --------------
P: checks/junoser edge2.ussfo03.blade-group.net
C: /app/jerikan
O:
E: Invalid syntax: set system syslog archive size 10m files 10 word-readable
S: 1
Integration into GitLab CI
The next step is to compile the templates using a CI. As we are using
GitLab, Jerikan ships with a .gitlab-ci.yml
file. When we need to make a change, we create a dedicated branch and
a merge request. GitLab compiles the templates using the same
environment we use on our laptops and store them as an artifact.
Merge request to add a new port in USSFO03. The templates were compiled successfully but approval from another team member is still required to merge.
Before approving the merge request, another team member looks at the
changes in data and templates but also the differences for the
generated configuration files:
The change configures a port on the Juniper device, adds records to DNS, and updates NetBox with the new IP addresses (not shown).
Ansible
After Jerikan has built the configuration files, Ansible takes
over. It is also packaged as a Docker image to avoid the trouble to
maintain the right Python virtual environment and ensure everyone is
using the same versions.
InventoryJerikan has generated an inventory file. It contains all the managed
devices, the variables defined for each of them and the groups
converted to Ansible groups:
in-sync is a special group for devices which configuration should
match the golden configuration. Daily and unattended, Ansible should
be able to push configurations to this group. The mid-term goal is to
cover all devices.
none is a special device for tasks not related to a specific host.
This includes synchronizing NetBox, IRR objects, and the DNS,
updating the RPKI, and building the geofeed files.
Playbook
We use a single playbook for all devices. It is described in the
ansible/playbooks/site.yaml file.
Here is a shortened version:
A host executes only one of the play. For example, a Junos device
executes the blade.junos role. Once a play has been executed, the
device is added to the done group and the other plays are skipped.
The playbook can be executed with the configuration files generated by
the GitLab CI using the ./run-ansible-gitlab command. This is a
wrapper around Docker and the ansible-playbook command and it
accepts the same arguments. To deploy the configuration on the edge
devices for the SK1 datacenter in check mode, we use:
We avoid using collections from Ansible Galaxy, the exception
being collections to connect and interact with vendor devices, like
cisco.iosxr collection. The quality of Ansible
Galaxy collections is quite random and it is an additional
maintenance burden. It seems better to write roles tailored to our
needs. The collections we use are in
ci/ansible/ansible-galaxy.yaml. We use
Mitogen to get a 10 speedup on Ansible executions on Linux
hosts.
We also have a few playbooks for operational purpose: upgrading the OS
version, isolate an edge router, etc. We were also planning on how to
add operational checks in roles: are all the BGP sessions up? They
could have been used to validate a deployment and rollback if there is
an issue.
Currently, our playbooks are run from our laptops. To keep tabs, we
are using ARA. A weekly dry-run on devices in the in-sync group
also provides a dashboard on which devices we need to run Ansible
on.
Configuration data and templatesJerikan ships with pre-populated data and templates matching the
configuration of our USSFO03 and SK1 datacenters. They do not exist
anymore but, we promise, all this was used in production back in the
days!
The latest iteration of our network infrastructure for SK1, USSFO03, and future data centers. The production network is using BGPttH using a spine-leaf fabric. The out-of-band network is using a simple L2 design, using the spanning tree protocol, as well as a set of console servers.
Notably, you can find the configuration for:
our edge routers
Some are running on Junos, like edge2.ussfo03, the others on
IOS-XR, like edge1.sk1. The implemented functionalities are
similar in both cases and we could swap one for the other. It
includes the BGP configuration for transits, peerings, and IX as
well as the associated BGP policies. PeeringDB is queried to get
the maximum number of prefixes to accept for peerings. bgpq3 and a
containerized IRRd help to filter received routes. A firewall is
added to protect the routing engine. Both IPv4 and IPv6 are
configured.
our BGP-based fabric
BGP is used inside the datacenter8 and is extended on
bare-metal hosts. The configuration is automatically derived from
the device location and the port number.9 Top-of-the-rack
devices are using passive BGP sessions for ports towards servers.
They are also serving a provisioning network to let them boot using
DHCP and PXE. They also act as a DHCP server. The design is
multivendor. Some devices are running Cumulus Linux, like
to1-p1.ussfo03, while some others are running Junos, like
to1-p2.ussfo03.
our out-of-band fabric
We are using Cisco Catalyst 2960 switches to build an L2 out-of-band
network. To provide redundancy and saving a few bucks on wiring, we
build small loops and run the spanning-tree protocol. See
ob1-p1.ussfo03. It is redundantly connected to our gateway
servers. We also use OpenGear devices for console access. See
con1-n1.ussfo03
our administrative gateways
These Linux servers have multiple purposes: SSH jump boxes, rescue
connection, direct access to the out-of-band network, zero-touch
provisioning of network devices,10 Internet access for management
flows, centralization of the console servers using Conserver,
and API for autoconfiguration of BGP sessions for bare-metal
servers. They are the first servers installed in a new datacenter
and are used to provision everything else. Check both the generated
files and the associated Ansible tasks.
Ansible does not even provide a line number when there is an
error in a template. You may need to find the problem by
bisecting.
$ ansible --version
ansible 2.10.8[ ]$ cat test.j2
Hello name !$ ansible all -i localhost, \> --connection=local\> -m template \> -a "src=test.j2 dest=test.txt"localhost FAILED! => "changed": false, "msg": "AnsibleUndefinedVariable: 'name' is undefined"
You may recognize the same concepts as in Hiera, the
hierarchical key-value store from Puppet. At first, we were
using Jerakia, a similar independent store exposing an HTTP
REST interface. However, the lookup overhead is too large for our
use. Jerikan implements the same functionality within a Python
function.
The list of available filters is mangled inside
jerikan/jinja.py. This is a remain of the
fact we do not maintain Jerikan as a standalone software.
This is a bit confusing: we have a store() filter and a
store() function. With Jinja2, filters and functions live in
two different namespaces.
We are using a fork with some modifications to be able to
validate our configurations and exposing an HTTP service to
reduce the time spent on each configuration check.
There is a trend in network automation to automate a
configuration subset, for example by having a playbook to create a
new BGP session. We believe this is wrong: with time, your
configuration will get out-of-sync with its expected state,
notably hand-made changes will be left undetected.
We also have some datacenters using BGP EVPN VXLAN at
medium-scale using Juniper devices. As they are still in
production today, we didn t include this feature but we may
publish it in the future.
In retrospect, this may not be a good idea unless you are
pretty sure everything is uniform (number of switches for each
layer, number of ports). This was not our case. We now think it is
a better idea to assign a prefix to each device and write it in
the source of truth.
Non-linux based devices are upgraded and configured
unattended. Cumulus Linux devices are automatically upgraded on
install but the final configuration has to be pushed using
Ansible: we didn t want to duplicate the configuration process
using another tool.
Kubernetes is about giving up control. As someone who likes to understand what s going on that s made it hard for me to embrace it. I ve also mostly been able to ignore it, which has helped. However I m aware it s incredibly popular, and there s some infrastructure at work that uses it. While it s not my responsibility I always find having an actual implementation of something is useful in understanding it generally, so I decided it was time to dig in and learn something new.
First up, I should say I understand the trade-off here about handing a bunch of decisions off to Kubernetes about the underlying platform allowing development/deployment to concentrate on a nice consistent environment. I get the analogy with the shipping container model where you can abstract out both sides knowing all you have to do is conform to the TEU API. In terms of the underlying concepts I ve got some virtualisation and container experience, so I m not coming at this as a complete newcomer. And I understand multi-site dynamically routed networks.
That said, let s start with a basic goal. I d like to understand k8s (see, I can be cool and use the short name) enough to be comfortable with what s going on under the hood and be able to examine a running instance safely (i.e. enough confidence about pulling logs, probing state etc without fearing I might modify state). That ll mean when I come across such infrastructure I have enough tools to be able to hopefully learn from it.
To do this I figure I ll need to build myself a cluster and deploy some things on it, then poke it. I ll start by doing so on bare metal; that removes variables around cloud providers and virtualisation and gives me an environment I know is isolated from everything else. I happen to have a GMK NucBox available, so I ll use that.
As a first step I m aiming to get a single node cluster deployed running some sort of web accessible service that is visible from the rest of my network. That should mean I ve covered the basics of a Kubernetes install, a running service and actually making it accessible.
Of course I m running Debian. I ve got a Bullseye (Debian 11) install - not yet released as stable, but in freeze and therefore not a moving target. I wanted to use packages from Debian as much as possible but it seems that the bits of Kubernetes available in main are mostly just building blocks and not a great starting point for someone new to Kubernetes. So to do the initial install I did the following:
# Install docker + nftables from Debian
apt install docker.io nftables
# Add the Kubernetes repo and signing key
curl -s https://packages.cloud.google.com/apt/doc/apt-key.gpg > /etc/apt/k8s.gpg
cat > /etc/apt/sources.list.d/kubernetes.list <<EOF
deb [signed-by=/etc/apt/k8s.gpg] https://apt.kubernetes.io/ kubernetes-xenial main
EOF
apt update
apt install kubelet kubeadm kubectl
That resulted in a 1.21.1-00 install, which is current at the time of writing. I then used kubeadm to create the cluster:
The extra parameters were to make the API server externally accessible from the host. I don t know if that was a good idea or not at this stage
kubeadm spat out a bunch of instructions but the key piece was about copying the credentials to my user account. So I did:
noodles@udon:~$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
udon NotReady control-plane,master 4m31s v1.21.1
Ooooh. But why s it NotReady? Seems like it s a networking issue and I need to install a networking provider. The documentation on this is appalling. Flannel gets recommended as a simple option but then turns out to need a --pod-network-cidr option passed to kubeadm and I didn t feel like cleaning up and running again (I ve omitted all the false starts it took me to get to this point). Another pointer was to Weave so I decided to try that with the following magic runes:
(I believe what that s doing is the first 3 lines create a password and store it into the internal Kubernetes config so the weave pod can retrieve it. The final line then grabs a YAML config from Weaveworks to configure up weave. My intention is to delve deeper into what s going on here later; for now the primary purpose is to get up and running.)
As I m running a single node cluster I then had to untaint my control node so I could use it as a worker node too:
These are all things I m going to have to learn about, but for now I ll nod and smile and pretend I understand.
Now I want to actually deploy something to the cluster. I ended up with a simple HTTP echoserver (though it s not entirely clear that s actually the source for what I ended up pulling):
$ kubectl create deployment hello-node --image=k8s.gcr.io/echoserver:1.10
deployment.apps/hello-node created
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
hello-node-59bffcc9fd-8hkgb 1/1 Running 0 36s
$ kubectl expose deployment hello-node --type=NodePort --port=8080
$ kubectl get services
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
hello-node NodePort 10.107.66.138 <none> 8080:31529/TCP 1m
Looks good. And to test locally:
curl http://10.107.66.138:8080/
Hostname: hello-node-59bffcc9fd-8hkgb
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=192.168.53.147
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://10.107.66.138:8080/
Request Headers:
accept=*/*
host=10.107.66.138:8080
user-agent=curl/7.74.0
Request Body:
-no body in request-
Neat. But my external network is 192.168.53.0/24 and that s a 10.* address so how do I actually make it visible to other hosts?
What I seem to need is an Ingress Controller which provide some sort of proxy between the outside world and pods within the cluster. Let s pick nginx because at least I have some vague familiarity with that and it seems like it should be able to do a bunch of HTTP redirection to different pods depending on the incoming request.
i.e. incoming requests to http://udon.mynetwork/ should go to the hello-node on port 8080. I applied this:
$ kubectl apply -f hello-ingress.yaml
ingress.networking.k8s.io/example-ingress created
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
example-ingress <none> udon.mynetwork 80 3m8s
No address? What have I missed? Let s check the nginx service, which apparently lives in the ingress-nginx namespace:
noodles@udon:~$ kubectl get services -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.9.41 <pending> 80:32740/TCP,443:30894/TCP 13h
ingress-nginx-controller-admission ClusterIP 10.111.16.129 <none> 443/TCP 13h
<pending> does not seem like something I want. Digging around it seems I need to configure the external IP. So I do:
noodles@udon:~$ kubectl get services -n ingress-nginx
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
ingress-nginx-controller LoadBalancer 10.96.9.41 192.168.53.147 80:32740/TCP,443:30894/TCP 14h
ingress-nginx-controller-admission ClusterIP 10.111.16.129 <none> 443/TCP 14h
noodles@udon:~$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
example-ingress <none> udon.mynetwork 192.168.53.147 80 14h
Let s try a curl from a remote host:
curl http://udon.mynetwork/
Hostname: hello-node-59bffcc9fd-8hkgb
Pod Information:
-no pod information available-
Server values:
server_version=nginx: 1.13.3 - lua: 10008
Request Information:
client_address=192.168.0.5
method=GET
real path=/
query=
request_version=1.1
request_scheme=http
request_uri=http://udon.mynetwork:8080/
Request Headers:
accept=*/*
host=udon.mynetwork
user-agent=curl/7.64.0
x-forwarded-for=192.168.53.136
x-forwarded-host=udon.mynetwork
x-forwarded-port=80
x-forwarded-proto=http
x-real-ip=192.168.53.136
x-request-id=6aaef8feaaa4c7d07c60b2d05c45f75c
x-scheme=http
Request Body:
-no body in request-
Ok, so that seems like success. I ve got a single node cluster running a single actual application pod (the echoserver) and exporting it to the outside world. That s enough to start poking under the hood. Which is for another post, as this one is already getting longer than I d like. I ll just leave some final thoughts of things I need to work out:
What s going on with the networking?
Where s the IPv6 (the host in question has native IPv6 routing)?
How do I deploy my own application pod?
I should look at a multiple host setup (i.e. a real cluster).
How much of this goes away if I use a cloud provider like AWS to run the cluster?
Can I do this with the Debian Kubernetes packages?
My newsletter Le Courrier du hacker (3,800 subscribers, 176 issues) is 3 years old and Mailchimp costs were becoming unbearable for a small project ($50 a month, $600 a year), with still limited revenues nowadays. Switching to the Open Source Mailtrain plugged to the AWS Simple Email Service (SES) will dramatically reduce the associated costs.
First things first, thanks a lot to Pierre-Gilles Leymarie for his own article about switching to Mailtrain/SES. I owe him (and soon you too) so much. This article will be a step-by-step about how to set up Mailtrain/SES on a dedicated server running Linux.
What s the purpose of this article?
Mailchimp is more and more expensive following the growth of your newsletter subscribers and you need to leave it. You can use Mailtrain, a web app running on your own server and use the AWS SES service to send emails in an efficient way, avoiding to be flagged as a spammer by the other SMTP servers (very very common, you can try but you have been warned against
Prerequisites
You will need the following prerequisites :
An AWS account with admin rights
Full control over the domain name you use to send your newsletter
A baremetal or virtual Linux Debian server you have the root access to
NodeJS installed (8x and 10x are ok with Mailtrain)
A MySQL/MariaDB instance with the root access to
Redis 3x (not 5) if you want to use Redis (not mandatory)
Steps
This is a fairly straightforward setup if you know what you re doing. In the other case, you may need the help of a professional sysadmin.
You will need to complete the following steps in order to complete your setup:
Configure AWS SES
Configure your server by:
configuring your database
install Mailtrain
configuring your web server
Configure your Mailtrain setup
Configure AWS SES
Verify your domain
You need to configure the DKIM to certify that the emails sent are indeed from your own domain. DKIM is mandatory, it s the de-facto standard in the mail industry.
Ask to verify your domain
Ask AWS SES to verify a domain
Generate the DKIM settings
Generate the DKIM settings
Use the DKIM settings
Now you have your DKIM settings and Amazon AWS is waiting for finding the TXT field in your DNS zone.
Configure your DNS zone to include DKIM settings
I can t be too specific for this section because it varies A LOT depending on your DNS provider. The keys is: as indicated by the previous image you have to create one TXT record and two CNAME records in your DNS zone. The names, the types and the values are indicated by AWS SES.
If you don t understand what s going here, there is a high probabiliy you ll need a system administrator to apply these modifications and the next ones in this article.
Am I okay for AWS SES ?
As long as the word verified does not appear for your domain, as shown in the image below, something is wrong. Don t wait too long, you have a misconfiguration somewhere.
AWS SES pending verification
When your domain is verified, you ll also receive an email to inform you about the successful verification.
SMTP settings
The last step is generating your credentials to use the AWS SES SMTP server. IT is really straightforward, providing the STMP address to use, the port, and a pair of username/password credentials.
AWS SES SMTP settings and credentials
Just click on Create My SMTP Credentials and follow the instructions. Write the SMTP server address somewhere and store the file with credentials on your computer, we ll need them below.
Configure your server
As we said before, we need a baremetal server or a virtual machine running a recent Linux.
Configure your MySQL/MariaDB database
We create a user mailtrain having all rights on a new database mailtrain.
MariaDB [(none)]> create database mailtrain;
Query OK, 1 row affected (0.00 sec)
MariaDB [(none)]> CREATE USER 'mailtrain' IDENTIFIED BY 'V3rYD1fF1cUlTP4sSW0rd!';
Query OK, 0 rows affected (0.01 sec)
MariaDB [(none)]> GRANT ALL PRIVILEGES ON mailtrain.* TO 'mailtrain'@localhost IDENTIFIED BY 'V3rYD1fF1cUlTP4sSW0rd!';
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> FLUSH PRIVILEGES;
Query OK, 0 rows affected (0.00 sec)
MariaDB [(none)]> show databases;
+--------------------+
Database
+--------------------+
information_schema
mailtrain
mysql
performance_schema
+--------------------+
6 rows in set (0.00 sec)
MariaDB [(none)]> Bye
Configure your web server
I use Nginx and I ll give you the complete setup for it, including generating Let s Encrypt.
Configure Let s Encrypt
You need to stop Nginx as root:
systemctl stop nginx
Then get the certificate only, I ll give the Nginx Vhost configuration:
certbot certonly -d mailtrain.toto.com
Install Mailtrain
On your server create the following directory:
mkdir -p /var/www/ cd /var/www wget https://github.com/Mailtrain-org/mailtrain/archive/refs/tags/v1.24.1.tar.gz tar zxvf v1.24.1.tar.gz
Modify the file /var/www/mailtrain/config/production.toml to use the MySQL settings:
Now Mailtrain is launched and should be running. Yeah I know it s ugly to launch like this (root process in a screen, etc) you can improve security with the following commands:
To register the following systemd unit and to launch the new Mailtrain daemon, use the following commands (do not forget to kill your screen session if you used it before):
Now Mailtrain is running under the classic user mailtrain of the mailtrain system group.
Configure the Nginx Vhost configuration for your domain
Here is my configuration for the Mailtrain Nginx Vhost:
This Nginx vhost will redirect all http requests coming to the Mailtrain process running on the 3000 port. Now it s time to setup Mailtrain!
Setup Mailtrain
You should be able to access your Mailtrain at https://mailtrain.toto.com
Mailtrain is quite simple to configure, Here is my mailer setup. Mailtrain just forwards emails to AWS SES. We only have to plug Mailtrain to AWS SES.
Mailtrain mailer setup
The hostname is provided by AWS SES in the STMP Settings section. Use the 465 port and USE TLS option. Next is providing your AWS SES username and password you generated above and stored somewhere on your computer.
One of the issues I encountered is the AWS SES rate limit. Send too many emails too fast will get you flagged as a spammer.
So I had to throttle Mailtrain. Because I m a lazy man, I asked Pierre-Gilles Leymarie his setup. Quite easier than determining myself the good one. Here is my setup. Works fine for my soon-to-be 4k subscribers. The idea is: if your AWS SES lets you know you send too fast then just slow down.
Mailtrain to throttle sending emails to AWS SES
Conclusion
That s it! You re ready! Almost. You need an HTML template for your newsletter and a list of subscribers. Buf if you re not new in the newsletter field, fleeing Mailchimp because of their expensive prices, you should have them both already.
After sending almost ten issues with this setup, I m really happy with it. Open/click rates are the same.
When leaving Mailchimp, do not leave any list of subscribers because they ll charge you $8 for a 0 to 500 contacts, that s crazy expensive!
About the author
Redox-dependent inactivations are actually rather common in the field of metalloenzymes, and electrochemistry can be an extremely powerful tool to study them, providing one can analyze the data quantitatively. The point of this point is to teach the reader how to do so using QSoas. For more general information about redox inactivations and how to study them using electrochemical techniques, the reader is invited to read the review del Barrio and Fourmond, ChemElectroChem 2019.
This post is a tutorial to learn the analysis of data coming from the study of the redox-dependent substrate inhibition of periplasmic nitrate reductase NapAB, which has the advantage of being relatively simple. The whole processed is discussed in Jacques et al, BBA, 2014. What you need to know in order to follow this tutorial is the following:
the whole inactivation/reactivation process can be modelled by a simple reversible reaction:
$$ \mathrm A \rightleftharpoons \mathrm I $$
A is the active form, I the inactive form;
the forward rate constant is \(k_i(E)\) (dependent on potential) and the backward rate constant is \(k_a(E)\), also dependent on potential;
the experiment is done in a series of 5 steps at 3 different potentials: \(E_0\) then \(E_1\) then \(E_2\) then \(E_1\) then, finally, \(E_0\);
the enzyme is assumed to be fully active at the beginning of the first step;
a single experiment is used to obtain the values of \(k_i\) and \(k_a\) for the three potentials (although not reliably for the value at \(E_0\)
the current given by the active species depends on potential (and it is negative because the enzyme catalyzes a reduction), and the inactive species gives no current;
in addition to the reversible reaction above, there is an irreversible, potential-dependent loss.
You can download the data files from the GitHub repository. Before fitting the data to determine the values of the rate constants at the potentials of the experiment, we will first subtract the background current, assuming that the respective contributions of faradaic and non-faradaic currents is additive. Start QSoas, go to the directory where you saved the files, and load both the data file and the blank file thus:
QSoas> cd
QSoas> load 27.oxw
QSoas> load 27-blanc.oxw
QSoas> S 1 0
(after the first command, you have to manually select the directory in which you downloaded the data files). The S 1 0 command just subtracts the dataset 1 (the first loaded) from the dataset 0 (the last loaded), see more there. blanc is the French for blank...
Then, we remove a bit of the beginning and the end of the data, corresponding to one half of the steps at \(E_0\), which we don't exploit much here (they are essentially only used to make sure that the irreversible loss is taken care of properly). This is done using strip-if:
QSoas> strip-if x<30 x>300
Then, we can fit ! The fit used is called fit-linear-kinetic-system, which is used to fit kinetic models with only linear reactions (like here) and steps which change the values of the rate constants but do not instantly change the concentrations. The specific command to fit the data is:
The /species=2 indicates that there are two species (A and I). The /steps=0,1,2,1,0 indicates that there are 5 steps, with three different conditions (0 to 2) in order 0,1,2,1,0. This fits needs a bit of setup before getting started. The species are numbered, 1 and 2, and the conditions (potentials) are indicated by #0, #1 and #2 suffixes.
The I_1 and I_2 are the currents for the species 1 and 2, so something for 1 (active form) and 0 for 2 (inactive form).
Moreover, the parameters I_2_#0 (and _#1, _#2) should be fixed and not free (since we don't need to adjust a current for the inactive form).
The k_11 and k_22 correspond to species-specific irreversible loss. It is generally best to leave them fixed to 0.
k_12 is the formation of 2 (I) from 1 (A), and k_21 is the formation of A from I. Their values will be determined for the three conditions. The default values should work here.
The k_loss parameters are the rates of irreversible loss that apply indiscriminately on all species (unlike k_11 and k_22). They are adjusted and ther default values should work too.
alpha_1_0 and alpha_2_0 are the initial concentrations of species 1 and 2, so they should be fixed to 1 and 0.
Last, the xstart_a and (_b, _c, _d and _e) correspond to the starting times for the steps, here, 0, 60, 120, 210 and 270.
For the sake of simplicity, you can also simply load the starting-parameters.params parameters to have all setup the correct way. Then, just hit Fit, enjoy this moment when QSoas works and you don't have to... The screen should now look like this:
Now, it's done ! The fit is actually pretty good, and you can read the values of the inactivation and reactivation rate constants from the fit parameters.
You can train also on the 21.oxw and 21-blanc.oxw files. Usually, re-loading the best fit parameters from other potentials as starting parameters work really well. Gathering the results of several fits into a real curve of rate constants as a function of potentials is left as an exercise for the reader (or maybe a later post), although you may find these series of posts useful in this context !
About QSoas
QSoas is a powerful open source data analysis program that focuses on flexibility and powerful fitting capacities. It is released under the GNU General Public License. It is described in Fourmond, Anal. Chem., 2016, 88 (10), pp 5050 5052. Current version is 3.0. You can download its source code there (or clone from the GitHub repository) and compile it yourself, or buy precompiled versions for MacOS and Windows there.
KDE Impressions
These days, I often hear a lot about Wayland. And how much of effort is being put into it; not just by the Embedded world but also the usual Desktop systems, namely KDE and GNOME.
In recent past, I switched back to KDE and have been (very) happy about the switch. Even though the KDE 4 (and initial KDE 5) debacle had burnt many, coming back to a usable KDE desktop is always a delight. It makes me feel home with the elegance, while at the same time the flexibility, it provides. It feels so nice to draft this blog article from Kwrite + VI Input Mode
Thanks to the great work of the Debian KDE Team, but Norbert Preining in particular, who has helped bring very up-to-date KDE packages into Debian. Right now, I m on a Plamsa 5.21.1 desktop, which is recent by all standards.
Wayland
Almost all the places in the Linux world these days are busy with integrating Wayland as the primary display service. Not sure what the current status on the GNOME side is but I definitely keep trying KDE + Wayland with every release.
I keep trying with every release because it still is not prime for daily use. And it makes me get back to X11, no matter how dated some may call. Fact is, X11 still shines to me as an end-user.
Glitches with Wayland still are (Based on this week s test on Plasma 5.21.1):
Horrible performance compared to X11
Very crashy, especially when hotplugging secondary display. Plasma would just crash. X11 is very resilient to such things, part of the reason I can think is the age of the codebase.
Many many applications still need to be fixed for Wayland. Or Wayland needs to accomodate them in some way. XWayland does not really feel like the answer.
And while KDE keeps insisting users to switch to Wayland, as that s where all the new enhancements and fixes are put in, someone like me still needs to stick to X11 for the time being. So to get my shiny new LG 27" 4K Monitor (3840x2160 60.00*+) to work without too much glitch, I had to live with an alias:
$ alias grep xrandr
alias rrs_xrandr_lg='xrandr --output DP-1 --mode 3840x2160 --scale .75x.75'
18:31
Plasma 5.21
On the brighter side, the Plasma 5.21.1 release brings some nice enhancements in other areas.
The new Plasma theme, Breeze Twilight, is a good blend of Light + Dark.
I also appreciate the work put in by Michail Vourlakos. The KDE project is lucky to have a developer/designer like him. His vision and work into the KDE desktop is well beyond a writing by me.
$ usystemctl status plasma-plasmashell.service
plasma-plasmashell.service - KDE Plasma Workspace
Loaded: loaded (/usr/lib/systemd/user/plasma-plasmashell.service; enabled; vendor preset: enabled)
Active: active (running) since Fri 2021-02-26 18:34:23 IST; 13s ago
Main PID: 501806(plasmashell)
Tasks: 21(limit: 18821)
Memory: 759.8M
CPU: 13.706s
CGroup: /user.slice/user-1000.slice/user@1000.service/session.slice/plasma-plasmashell.service
501806 /usr/bin/plasmashell --no-respawn
Feb 26 18:35:00 priyasi plasmashell[501806]: qml: recreating buttons
Feb 26 18:35:21 priyasi plasmashell[501806]: qml: recreating buttons
Feb 26 18:35:49 priyasi plasmashell[501806]: qml: recreating buttons
Feb 26 18:35:57 priyasi plasmashell[501806]: qml: recreating buttons
18:36
OBS - Open Build Service
I should also thank the OpenSUSE folks for the OBS work. It has enabled the close equivalent (or better, in my experience) of PPAs for Debian. And that is what has enabled developers like Norbert to easily and quickly be able to deliver the entire KDE suite.
OBS - Some detail
Christian asked for some more details on the OBS side of things, of my view. I m updating this article with it because the comment system may not always be reliable and I hate losing content.
Having been using OBS myself, and also others in the Debian community who are making use of it, I surely think we as project should consider making use of OBS.
Given that OBS is Free Software, it is a perfect fit for Debian. Gitlab is another example of what we ve made available in Debian.
OBS is divided into multiple parts
OBS Server
OBS DoD service
OBS Publisher
OBS Workers
OBS Warden
OBS Rep Server
For every Debian release I care about, I add an OBS project per release. So I have OBS projects for: Sid, Bullseye, Buster, Jessie.
Now, say you have a package, foo . You prep your package and enable all the releases that you want to build the package for. So the same package gets built, in separate clean environments, for every release I mentioned as an example above. You don t have to manually trigger the build for every release/every architcture. You should add the release (as projects) in OBS, set their supported architectures, and then add those enabled release projets as bits to your package.
Every build involves:
Creating a new chroot for each build
Building the package
Builds can be scattered across multiple hosts, known as workers in OBS terminology. Your workers are independent machine entities, supporting different architectures. The machines can be Bare-Metal ones, VMs, even containers. So this allows for very nice scale-in and scale-out. There may be auto-scaling too but that is something worth investigating.
Think of things like cross architecture builds. Let s assume the cloud vendors decide to donate resources to the Debian project. We could enable OBS worker instances on the respective clouds (different architectures) and plug them into the master OBS instance that Debian hosts. Fully distributed. Similarly, big hardware vendors willing to donate compute resources could house them in their premises and Debian could just easily establish a connection to them. All of this just a TCP connection away.
So when I look at the features of OBS, from the point of view of Debian, I like it more. Extensibility won t be an issue. Supporting a new Debian release would just be a matter of bootstrapping the Debian release as a project in OBS, and then all done. The single effort of setting of the target release project is a one time job, and then all can leverage it.
The PPA was a long craved feature missing in Debian, in my opinion. OBS allows to not just fulfil that gap but also extend it in a very easy way.
Andrew Lee had put in a nice video presentation about the same @ Debconf 20
I'm sorry to announce that I gave up on the Fairphone series and
switched to a Google Phone (Pixel 4a) running CalyxOS.
Problems in fairy land
My fairphone2, even if it is less than two years
old, is having major problems:
from time to time, the screen flickers and loses "touch" until I
squeeze it back together
the camera similarly disconnects regularly
even when it works, the camera is... pretty bad: low light is
basically unusable, it's slow and grainy
the battery can barely keep up for one day
the cellular coverage is very poor, in Canada: I lose signal at the
grocery store and in the middle of my house...
Some of those problems are known: the Fairphone 2 is old now. It was
probably old even when I got it. But I can't help but feel a little
sad to let it go: the entire point of that device was to make it easy
to fix. But alas, because it's sold only in Europe, local stores don't
carry replacement parts. To be fair, Fairphone did offer to fix the
device, but with a 2 weeks turnaround, I had to get another phone
anyways.
I did actually try to buy a fairphone3, from
Clove. But they did some crazy validation routine. By email, they
asked me to provide a photo copy of a driver's license and the credit
card, arguing they need to do this to combat fraud. I found that
totally unacceptable and asked them to cancel my order. And because
I'm not sure the FP3 will fix the coverage issues, I decided to just
give up on Fairphone until they officially ship to the Americas.
Do no evil, do not pass go, do not collect 200$
So I got a Google phone, specifically a Pixel 4a. It's a nice device,
all small and shiny, but it's "plasticky" - I would have prefered
metal, but it seems you need to pay much, much more to get that (in
the Pixel 5).
In any case, it's certainly a better form factor than the Fairphone 2:
even though the screen is bigger, the device itself is actually
smaller and thinner, which feels great. The OLED screen is beautiful,
awesome contrast and everything, and preliminary tests show that the
camera is much better than the one on the Fairphone 2. (The be fair,
again, that is another thing the FP3 improved significantly. And that
is with the stock Camera app from CalyxOS/AOSP, so not as good as the
Google Camera app, which does AI stuff.)
CalyxOS: success
The Pixel 4a not not supported by LineageOS: it seems every time
I pick a device in that list, I manage to miss the right device by one
(I bought a Samsung S9 before, which is also unsupported, even though
the S8 is). But thankfully, it is supported by CalyxOS.
That install was a breeze: I was hesitant in playing again with
installing a custom Android firmware on a phone after fighting with
this quite a bit in the past (e.g. htc-one-s,
lg-g3-d852). But it turns out their install
instructions, mostly using a AOSP alliancedevice-flasher
works absolutely great. It assumes you know about the commandline, and
it does require to basically curl sudo (because you need to
download their binary and run it as root), but it Just. Works. It
reminded me of how great it was to get the Fairphone with TWRP
preinstalled...
Oh, and kudos to the people in #calyxos on Freenode: awesome tech
support, super nice folks. An amazing improvement over the ambiance in
#lineageos!
Migrating data
Unfortunately, migrating the data was the usual pain in the back. This
should improve the next time I do this: CalyxOS ships with
seedvault, a secure backup system for Android 10 (or 9?) and
later which backs up everything (including settings!) with
encryption. Apparently it works great, and CalyxOS is also working on
a migration system to switch phones.
But, obviously, I couldn't use that on the Fairphone 2 running Android
7... So I had to, again, improvised. The first step was to install
Syncthing, to have an easy way to copy data around. That's easily
done through F-Droid, already bundled with CalyxOS (including the
privileged extension!). Pair the devices and boom, a magic portal to
copy stuff over.
The other early step I took was to copy apps over using the F-Droid
"find nearby" functionality. It's a bit quirky, but really helps in
copying a bunch of APKs over.
Then I setup a temporary keepassxc password vault on the
Syncthing share so that I could easily copy-paste passwords into
apps. I used to do this in a text file in Syncthing, but copy-pasting
in the text file is much harder than in KeePassDX. (I just picked
one, maybe KeePassDroid is better? I don't know.) Do keep a copy
of the URL of the service to reduce typing as well.
Then the following apps required special tweaks:
AntennaPod has an import/export feature: export on one end,
into the Syncthing share, then import on the other. then go to the
queue and select all episodes and download
the Signal "chat backup" does copy the secret key around, so
you don't get the "security number change" warning (even if it
prompts you to re-register) - external devices need to be relinked
though
AnkiDroid, DSub, Nextcloud, and Wallabag required copy-pasting
passwords
I tried to sync contacts with DAVx5 but that didn't work so well:
the account was setup correctly, but contacts didn't show up. There's
probably just this one thing I need to do to fix this, but since I
don't really need sync'd contact, it was easier to export a VCF file
to Syncthing and import again.
Known problems
One problem with CalyxOS I found is that the fragile little microg
tweaks didn't seem to work well enough for Signal. That was unexpected
so they encouraged me to file that as a bug.
The other "issue" is that the bootloader is locked, which makes it
impossible to have "root" on the device. That's rather unfortunate: I
often need root to debug things on Android. In particular, it made it
difficult to restore data from OSMand (see below). But I guess that
most things just work out of the box now, so I don't really need it
and appreciate the extra security. Locking the bootloader means full
cryptographic verification of the phone, so that's a good feature to
have!
OSMand still doesn't have a good import/export story. I ended up
sharing the Android/data/net.osmand.plus/files directory and
importing waypoints, favorites and tracks by hand. Even though maps
are actually in there, it's not possible for Syncthing to write
directly to the same directory on the new phone, "thanks" to the new
permission system in Android which forbids this kind of inter-app
messing around.Tracks are particularly a problem: my older OSMand setup had all those
folders neatly sorting those tracks by month. This makes it really
annoying to track every file manually and copy it over. I have mostly
given up on that for now, unfortunately. And I'll still need to
reconfigure profiles and maps and everything by hand. Sigh. I guess
that's a good clearinghouse for my old tracks I never use...
Update: turns out setting storage to "shared" fixed the issue, see
comments below!
Conclusion
Overall, CalyxOS seems like a good Android firmware. The install is
smooth and the resulting install seems solid. The above problems are
mostly annoyances and I'm very happy with the experience so far,
although I've only been using it for a few hours so this is very
preliminary.
It s the end of CentOS as we know it
Earlier this week, the CentOS project announced the shift to CentOS stream. In a nutshell, this means that they will discontinue being a close clone of RHEL along with security updates, and instead it will serve as a development branch of RHEL.
As you can probably imagine (or gleam from the comments in that post I referenced), a lot of people are unhappy about this.
One particular quote got my attention this morning while catching up on this week s edition of Linux Weekly News, under the distributions quotes section:
I have been doing this for 17 years and CentOS is basically my life s work. This was (for me personally) a heart wrenching decision. However, i see no other decision as a possibility. If there was, it would have been made.Johnny Hughes
I feel really sorry for this person and can empathize, I ve been in similar situations in my life before where I ve poured all my love and energy into something and then due to some corporate or organisational decisions (and usually poor ones), the project got discontinued and all that work that went into it vanishes into the ether. Also, 17 years is really long to be contributing to any one project so I can imagine that this must have been especially gutting.
Throw me a freakin bone here
I m also somewhat skeptical of how successful CentOS Stream will really be in any form of a community project. It seems that Red Hat is expecting that volunteers should contribute to their product development for free, and then when these contributors actually want to use that resulting product, they re expected to pay a corporate subscription fee to do so. This seems like a very lop-sided relationship to me, and I m not sure it will be sustainable in the long term. In Red Hat s announcement of CentOS Stream, they kind of throw the community a bone by saying In the first half of 2021, we plan to introduce low- or no-cost programs for a variety of use cases - it seems likely that this will just be for experimental purposes similar to the Windows Insider program and won t be of much use for production users at all.
Red Hat does point out that their Universal Base Image (UBI) is free to use and that users could just use that on any system in a container, but this doesn t add much comfort to the individuals and organisations who have contributed huge amounts of time and effort to CentOS over the years who rely on a stable, general-purpose Linux system that can be installed on bare metal.
Way forward for CentOS users
Where to from here? I suppose CentOS users could start coughing up for RHEL subscriptions. For many CentOS use cases that won t make much sense. They could move to another distribution, or fork/restart CentOS. The latter is already happening. One of the original founders of the CentOS project, Gregory Kurtzer, is now working on Rocky Linux, which aims to be a new free system built from the RHEL sources.
Some people from Red Hat and Canonical are often a bit surprised or skeptical when I point out to them that binary licenses are also important. This whole saga is yet another data point, but it proves that yet again. If Red Hat had from the beginning released RHEL with free sources and unobfuscated patches, then none of this would ve been necessary in the first place. And while I wish Rocky Linux all the success it aims to achieve, I do not think that working for free on a system that ultimately supports Red Hat s selfish eco-system is really productive or helpful.
The fact is, Debian is already a free enterprise-scale system already used by huge organisations like Google and many others, which has stable releases, LTS support and ELTS offerings from external organisations if someone really needs it. And while RHEL clones have come and gone through the years, Debian s mission and contract to its users is something that stays consistent and I believe Debian and its ideals will be around for as long as people need Unixy operating systems to run anywhere (i.e. a very long time).
While we sometimes fall short of some of our technical goals in Debian, and while we don t always agree on everything, we do tend to make great long-term progress, and usually in the right direction. We ve proved that our method of building a system together is sustainable, that we can do so reliably and timely and that we can collectively support it. From there on it can only get even better when we join forces and work together, because when either individuals or organisations contribute to Debian, they can use the end result for both private or commercial purposes without having to pay any fee or be encumbered by legal gotchas.
Don t get caught by greedy corporate motivations that will result in you losing years of your life s work for absolutely no good reason. Make your time and effort count and either contribute to Debian or give your employees time to do so on company time. Many already do and reap the rewards of this, and don t look back.
While Debian is a very container and virtualization friendly system, we ve managed to remain a good general-purpose operating system that manages to span use cases so vast that I d have to use a blog post longer than this one just to cover them.
And while learning a whole new set of package build chain, package manager and new organisational culture and so on can be uhm, really rocky at the start, I d say that it s a good investment with Debian and unlikely to be time that you ll ever felt was wasted. As Debian project leader, I m personally available to help answer any questions that someone might have if they are interested in coming over to Debian. Feel free to mail leader_AT_debian.org (replace _AT_ with @) or find me on the oftc IRC network with the nick highvoltage. I believe that together, we can make Debian the de facto free enterprise system, and that it would be to the benefit of all its corporate users, instead of tilting all the benefit to just one or two corporations who certainly don t have your best interests in mind.
Technology must be transparent in order to be knowable. Technology must be knowable in order for us to be able to consent to it in good faith. Good faith informed consent is necessary to preserving our (digital) autonomy.
Let s now look at this in reverse, considering first why informed consent is necessary to our digital autonomy.
Let s take the concept of our digital autonomy as being one of the highest goods. It is necessary to preserve and respect the value of each individual, and the collectives we choose to form. It is a right to which we are entitled by our very nature, and a prerequisite for building the lives we want, that fulfill us. This is something that we have generally agreed on as important or even sacred. Our autonomy, in whatever form it takes, in whatever part of our life it governs, is necessary and must be protected.
One of the things we must do in order to accomplish this is to build a practice and culture of consent. Giving consent saying yes is not enough. This consent must come from a place of understand to that which one is consenting. Informed consent is consenting to the unknowable. (1)
Looking at sexual consent as a parallel, even when we have a partner who discloses their sexual history and activities, we cannot know whether they are being truthful and complete. Let s even say they are and that we can trust this, there is a limit to how much even they know about their body, health, and experience. They might not know the extent of their other partners experience. They might be carrying HPV without symptoms; we rarely test for herpes.
Arguably, we have more potential to definitely know what is occurring when it comes to technological consent. Technology can be broken apart. We can share and examine code, schematics, and design documentation. Certainly, lots of information is being hidden from us a lot of code is proprietary, technical documentation unavailable, and the skills to process these things is treated as special, arcane, and even magical. Tracing the resource pipelines for the minerals and metals essential to building circuit boards is not possible for the average person. Knowing the labor practices of each step of this process, and understanding what those imply for individuals, societies, and the environments they exist in seems improbable at best.
Even though true informed consent might not be possible, it is an ideal towards which we must strive. We must work with what we have, and we must be provided as much as possible.
A periodic conversation that arises in the consideration of technology rights is whether companies should build backdoors into technology for the purpose of government exploitation. A backdoor is a hidden vulnerability in a piece of technology that, when used, would afford someone else access to your device or work or cloud storage or whatever. As long as the source code that powers computing technology is proprietary and opaque, we cannot truly know whether backdoors exist and how secure we are in our digital spaces and even our own computers, phones, and other mobile devices.
We must commit wholly to transparency and openness in order to create the possibility of as-informed-as-possible consent in order to protect our digital autonomy. We cannot exist in a vacuum and practical autonomy relies on networks of truth in order to provide the opportunity for the ideal of informed consent. These networks of truth are created through the open availability and sharing of information, relating to how and why technology works the way it does.
(1) Heintzman, Kit. 2020.
I grew up riding bikes with my friends, but I didn't keep it up once I went to
University. A couple of my friends persevered and are really good riders, even
building careers on their love of riding.
I bought a mountain bike in 2006 (a sort of "first pay cheque" treat after
changing roles) but didn't really ride it all that often until this year. Once
Lockdown began, I started going for early morning rides in order to get some
fresh air and exercise.
Once I'd got into doing that I decided it was finally time to buy a new bike.
I knew I wanted something more like a "hybrid" than a mountain bike but apart
from that I was clueless. I couldn't even name the top manufacturers.
Ross Burton a friend from the Debian
community suggested I take a look at Cotic, a small
UK-based manufacturer based in the peak district. Specifically their
Escapade
gravel bike. (A gravel bike, it turns out, is kind-of like a hybrid.)
My new Cotic Escapade
I did some due diligence, looked at some other options, put together a
spreadsheet etc but the Escapade was the clear winner. During the project I
arranged to have a socially distant cup of tea with my childhood friend Dan,
now a professional bike mechanic, who by coincidence arrived on his own Cotic
Escapade. It definitely seemed to tick all the boxes. I just needed to agonise
over the colour choices: Metallic Orange (a Cotic staple) or a Grey with some
subtle purple undertones. I was leaning towards the Grey, but ended up plumping
for the Orange.
I could just cover it under Red Hat UK s cycle to work scheme. I m very pleased
our HR dept is continuing to support the scheme, in these times when they also
forbid me from travelling to the office.
And so here we are. I m very pleased with it! Perhaps I'll write more about
riding, or post some pictures, going forward.
I had an old Nexus 4 phone that was expanding and decided to test some of the theories about battery combustion.
The first claim that often gets made is that if the plastic seal on the outside of the battery is broken then the battery will catch fire. I tested this by cutting the battery with a craft knife. With every cut the battery sparked a bit and then when I levered up layers of the battery (it seems to be multiple flat layers of copper and black stuff inside the battery) there were more sparks. The battery warmed up, it s plausible that in a confined environment that could get hot enough to set something on fire. But when the battery was resting on a brick in my backyard that wasn t going to happen.
The next claim is that a Li-Ion battery fire will be increased with water. The first thing to note is that Li-Ion batteries don t contain Lithium metal (the Lithium high power non-rechargeable batteries do). Lithium metal will seriously go off it exposed to water. But lots of other Lithium compounds will also react vigorously with water (like Lithium oxide for example). After cutting through most of the center of the battery I dripped some water in it. The water boiled vigorously and the corners of the battery (which were furthest away from the area I cut) felt warmer than they did before adding water. It seems that significant amounts of energy are released when water reacts with whatever is inside the Li-Ion battery. The reaction was probably giving off hydrogen gas but didn t appear to generate enough heat to ignite hydrogen (which is when things would really get exciting). Presumably if a battery was cut in the presence of water while in an enclosed space that traps hydrogen then the sparks generated by the battery reacting with air could ignite hydrogen generated from the water and give an exciting result.
It seems that a CO2 fire extinguisher would be best for a phone/tablet/laptop fire as that removes oxygen and cools it down. If that isn t available then a significant quantity of water will do the job, water won t stop the reaction (it can prolong it), but it can keep the reaction to below 100C which means it won t burn a hole in the floor and the range of toxic chemicals released will be reduced.
The rumour that a phone fire on a plane could do a China syndrome type thing and melt through the Aluminium body of the plane seems utterly bogus. I gave it a good try and was unable to get a battery to burn through it s plastic and metal foil case. A spare battery for a laptop in checked luggage could be a major problem for a plane if it ignited. But a battery in the passenger area seems unlikely to be a big problem if plenty of water is dumped on it to prevent the plastic case from burning and polluting the air.
I was not able to get a result that was even worthy of a photograph. I may do further tests with laptop batteries.
Old laptop
I ve been meaning to get a new laptop for a while now. My ThinkPad X250 is now 5 years old and even though it s still adequate in many ways, I tend to run out of memory especially when running a few virtual machines. It only has one memory slot, which I maxed out at 16GB shortly after I got it. Memory has been a problem in considering a new machine. Most new laptops have soldered RAM and local configurations tend to ship with 8GB RAM. Getting a new machine with only a slightly better CPU and even just the same amount of RAM as what I have in the X250 seems a bit wasteful. I was eyeing the Lenovo X13 because it s a super portable that can take up to 32GB of RAM, and it ships with an AMD Ryzen 4000 series chip which has great performance. With Lenovo s discount for Debian Developers it became even more attractive. Unfortunately that s in North America only (at least for now) so that didn t work out this time.
Enter Tongfang
I ve been reading a bunch of positive reviews about the Tuxedo Pulse 14 and KDE Slimbook 14. Both look like great AMD laptops, supports up to 64GB of RAM and clearly runs Linux well. I also noticed that they look quite similar, and after some quick searches it turns out that these are made by Tongfang and that its model number is PF4NU1F.
I also learned that a local retailer (Wootware) sells them as the Wootbook. I ve seen one of these before although it was an Intel-based one, but it looked like a nice machine and I was already curious about it back then. After struggling for a while to find a local laptop with a Ryzen CPU and that s nice and compact and that breaks the 16GB memory barrier, finding this one that jumped all the way to 64GB sealed the deal for me.
This is the specs for the configuration I got:
This configuration cost R18 796 ( 947 / $1122). That s significantly cheaper than anything else I can get that even starts to approach these specs. So this is a cheap laptop, but you wouldn t think so by using it.
I used the Debian netinstall image to install, and installation was just another uneventful and boring Debian installation (yay!). Unfortunately it needs the firmware-iwlwifi and firmare-amd-graphics packages for the binary blobs that drives the wifi card and GPU. At least it works flawlessly and you don t need an additional non-free display driver (as is the case with NVidia GPUs). I haven t tested the graphics extensively yet, but desktop graphics performance is very snappy. This GPU also does fancy stuff like VP8/VP9 encoding/decoding, so I m curious to see how well it does next time I have to encode some videos. The wifi upgrade was nice for copying files over. My old laptop maxed out at 300Mbps, this one connects to my home network between 800-1000Mbps. At this speed I don t bother connecting via cable at home.
I read on Twitter that Tuxedo Computers thinks that it s possible to bring Coreboot to this device. That would be yet another plus for this machine.
I ll try to answer some of my own questions about this device that I had before, that other people in the Debian community might also have if they re interested in this device. Since many of us are familiar with the ThinkPad X200 series of laptops, I ll compare it a bit to my X250, and also a little to the X13 that I was considering before. Initially, I was a bit hesitant about the 14 form factor, since I really like the portability of the 12.5 ThinkPad. But because the screen bezel is a lot smaller, the Wootbook (that just rolls off the tongue a lot better than the PF4NU1F ) is just slightly wider than the X250. It weighs in at 1.1KG instead of the 1.38KG of the X250. It s also thinner, so even though it has a larger display, it actually feels a lot more portable. Here s a picture of my X250 on top of the Wootbook, you can see a few mm of Wootbook sticking out to the right.
Card Reader
One thing that I overlooked when ordering this laptop was that it doesn t have an SD card reader. I see that some variations have them, like on this Slimbook review. It s not a deal-breaker for me, I have a USB card reader that s very light and that I ll just keep in my backpack. But if you re ordering one of these machines and have some choice, it might be something to look out for if it s something you care about.
Keyboard/Touchpad
On to the keyboard. This keyboard isn t quite as nice to type on as on the ThinkPad, but, it s not bad at all. I type on many different laptop keyboards and I would rank this keyboard very comfortably in the above average range. I ve been typing on it a lot over the last 3 days (including this blog post) and it started feeling natural very quickly and I m not distracted by it as much as I thought I would be transitioning from the ThinkPad or my mechanical desktop keyboard. In terms of layout, it s nice having an actual Insert button again. This is things normal users don t care about, but since I use mc (where insert selects files) this is a welcome return :). I also like that it doesn t have a Print Screen button at the bottom of my keyboard between alt and ctrl like the ThinkPad has. Unfortunately, it doesn t have dedicated pgup/pgdn buttons. I use those a lot in apps to switch between tabs. At leas the Fn button and the ctrl buttons are next to each other, so pressing those together with up and down to switch tabs isn t that horrible, but if I don t get used to it in another day or two I might do some remapping. The touchpad has en extra sensor-button on the top left corner that s used on Windows to temporarily disable the touchpad. I captured it s keyscan codes and it presses left control + keyscan code 93. The airplane mode, volume and brightness buttons work fine.
I do miss the ThinkPad trackpoint. It s great especially in confined spaces, your hands don t have to move far from the keyboard for quick pointer operations and it s nice for doing something quick and accurate. I painted a bit in Krita last night, and agree with other reviewers that the touchpad could do with just a bit more resolution. I was initially disturbed when I noticed that my physical touchpad buttons were gone, but you get right-click by tapping with two fingers, and middle click with tapping 3 fingers. Not quite as efficient as having the real buttons, but it actually works ok. For the most part, this keyboard and touchpad is completely adequate. Only time will tell whether the keyboard still works fine in a few years from now, but I really have no serious complaints about it.
Display
The X250 had a brightness of 172 nits. That s not very bright, I think the X250 has about the dimmest display in the ThinkPad X200 range. This hasn t been a problem for me until recently, my eyes are very photo-sensitive so most of the time I use it at reduced brightness anyway, but since I ve been working from home a lot recently, it s nice to sometimes sit outside and work, especially now that it s spring time and we have some nice days. At full brightness, I can t see much on my X250 outside. The Wootbook is significantly brighter even (even at less than 50% brightness), although I couldn t find the exact specification for its brightness online.
Ports
The Wootbook has 3x USB type A ports and 1x USB type C port. That s already quite luxurious for a compact laptop. As I mentioned in the specs above, it also has a full-sized ethernet socket. On the new X13 (the new ThinkPad machine I was considering), you only get 2x USB type A ports and if you want ethernet, you have to buy an additional adapter that s quite expensive especially considering that it s just a cable adapter (I don t think it contains any electronics).
It has one hdmi port. Initially I was a bit concerned at lack of displayport (which my X250 has), but with an adapter it s possible to convert the USB-C port to displayport and it seems like it s possible to connect up to 3 external displays without using something weird like display over usual USB3.
Overall remarks
When maxing out the CPU, the fan is louder than on a ThinkPad, I definitely noticed it while compiling the zfs-dkms module. On the plus side, that happened incredibly fast. Comparing the Wootbook to my X250, the biggest downfall it has is really it s pointing device. It doesn t have a trackpad and the touchpad is ok and completely usable, but not great. I use my laptop on a desk most of the time so using an external mouse will mostly solve that.
If money were no object, I would definitely choose a maxed out ThinkPad for its superior keyboard/mouse, but the X13 configured with 32GB of RAM and 128GB of SSD retails for just about double of what I paid for this machine. It doesn t seem like you can really buy the perfect laptop no matter how much money you want to spend, there s some compromise no matter what you end up choosing, but this machine packs quite a punch, especially for its price, and so far I m very happy with my purchase and the incredible performance it provides.
I m also very glad that Wootware went with the gray/black colours, I prefer that by far to the white and silver variants. It s also the first laptop I ve had since 2006 that didn t come with Windows on it.
The Wootbook is also comfortable/sturdy enough to carry with one hand while open. The ThinkPads are great like this and with many other brands this just feels unsafe. I don t feel as confident carrying it by it s display because it s very thin (I know, I shouldn t be doing that with the ThinkPads either, but I ve been doing that for years without a problem :) ).
There s also a post on Reddit that tracks where you can buy these machines from various vendors all over the world.
Dealing with the void during MiniDebConf Online #1
Between 28 and 31 May this year, we set out to create our first ever online MiniDebConf for Debian. Many people have been meaning to do something similar for a long time, but it just didn t work out yet. With many of us being in lock down due to COVID-19, and with the strong possibility looming that DebConf20 might have had to become an online event, we rushed towards organising the first ever Online MiniDebConf and put together some form of usable video stack for it.
I could go into all kinds of details on the above, but this post is about a bug that lead to a pretty nifty feature for DebConf20. The tool that we use to capture Jitsi calls is called Jibri (Jitsi Broadcasting Infrustructure). It had a bug (well, bug for us, but it s an upstream feature) where Jibri would hang up after 30s of complete silence, because it would assume that the call has ended and that the worker can be freed up again. This would result in the stream being ended at the end of every talk, so before the next talk, someone would have to remember to press play again in their media player or on the video player on the stream page. Hrmph.
Easy solution on the morning that the conference starts? I was testing a Debian Live image the night before in a KVM and thought that I might as well just start a Jitsi call from there and keep a steady stream of silence so that Jibri doesn t hang up.
It worked! But the black screen and silence on stream was a bit eery. Because this event was so experimental in nature, and because we were on such an incredibly tight timeline, we opted not to seek sponsors for this event, so there was no sponsors loop that we d usually stream during a DebConf event. Then I thought Ah! I could just show the schedule! .
The stream looked bright and colourful (and was even useful!) and Jitsi/Jibri didn t die. I thought my work was done. As usual, little did I know how untrue that was.
The silence was slightly disturbing after the talks, and people asked for some music. Playing music on my VM and capturing the desktop audio in to Jitsi was just a few pulseaudio settings away, so I spent two minutes finding some freely licensed tracks that sounded ok enough to just start playing on the stream. I came across mini-albums by Captive Portal and Cinema Noir, During the course of the MiniDebConf Online I even started enjoying those. Someone also pointed out that it would be really nice to have a UTC clock on the stream. I couldn t find a nice clock in a hurry so I just added a tmux clock in the meantime while we deal with the real-time torrent of issues that usually happens when organising events like this.
Speaking of issues, during our very first talk of the last day, our speaker had a power cut during the talk and abruptly dropped off. Oops! So, since I had a screenshare open from the VM to the stream, I thought I d just pop in a quick message in a text editor to let people know that we re aware of it and trying to figure out what s going on.
In the end, MiniDebConf Online worked out all right. Besides the power cut for our one speaker, and another who had a laptop that was way too under-powered to deal with video, everything worked out very well. Even the issues we had weren t show-stoppers and we managed to work around them.
DebConf20 Moves Online
For DebConf, we usually show a sponsors loop in between sessions. It s great that we give our sponsors visibility here, but in reality people see the sponsors loop and think Talk over! and then they look away. It s also completely silent and doesn t provide any additional useful information. I was wondering how I could take our lessons from MDCO#1 and integrate our new tricks with the sponsors loop. That is, add the schedule, time, some space to type announcements on the screen and also add some loopable music to it.
I used OBS before in making my videos, and like the flexibility it provides when working with scenes and sources. A scene is what you would think of as a screen or a document with its own collection of sources or elements. For example, a scene might contain sources such as a logo, clock, video, image, etc. A scene can also contain another scene. This is useful if you want to contain a banner or play some background music that is shared between scenes.
The above screenshots illustrate some basics of scenes and sources. First with just the DC20 banner, and then that used embedded in another scene.
For MDCO#1, I copied and pasted the schedule into a LibreOffice Impress slide that was displayed on the stream. Having to do this for all 7 days of DebConf, plus dealing with scheduling changes would be daunting. So, I started to look in to generating some schedule slides programmatically. Stefano then pointed me to the Happening Now page on the DebConf website, where the current schedule block is displayed. So all I would need to do in OBS was to display a web page. Nice!
Unfortunately the OBS in Debian doesn t have the ability to display web pages out of the box (we need to figure out CEF in Debian), but fortunately someone provides a pre-compiled version of the plugin called Linux Browser that works just fine. This allowed me to easily add the schedule page in its own scene.
Being able to display a web page solved another problem. I wasn t fond of having to type / manage the announcements in OBS. It would either be a bit prone to user error, and if you want to edit the text while the loop is running, you d have to disrupt the loop, go to the foreground scene, and edit the text before resuming the loop. That s a bit icky. Then I thought that we could probably just get that from a web page instead. We could host some nice html snippet in a repository in salsa, and then anyone could easily commit an MR to update the announcement.
But then I went a step further, use an etherpad! Then anyone in the orga team can quickly update the announcement and it would be instantly changed on the stream. Nice! So that small section of announcement text on the screen is actually a whole web browser with an added OBS filter to crop away all the pieces we don t want. Overkill? Sure, but it gave us a decent enough solution that worked in time for the start of DebConf. Also, being able to type directly on to the loop screen works out great especially in an emergency. Oh, and uhm the clock is also a website rendered in its own web browser :-P
So, I had the ability to make scenes, add elements and add all the minimal elements I wanted in there. Great! But now I had to figure out how to switch scenes automatically. It s probably worth mentioning that I only found some time to really dig into this right before DebConf started, so with all of this I was scrambling to find things that would work without too many bugs while also still being practical.
Now I needed the ability to switch between the scenes automatically / programmatically. I had never done this in OBS before. I know it has some API because there are Android apps that you can use to control OBS with from your phone. I discovered that it had an automatic scene switcher, but it s very basic. It can only switch based on active window, which can be useful in some cases, but since we won t have any windows open other than OBS, this tool was basically pointless.
After some quick searches, I found a plugin called Advanced Scene Switcher. This plugin can do a lot more, but has some weird UI choices, and is really meant for gamers and other types of professional streamers to help them automate their work flow and doesn t seem at all meant to be used for a continuous loop, but, it worked, and I could make it do something that will work for us during the DebConf.
I had a chicken and egg problem because I had to figure out a programming flow, but didn t really have any content to work with, or an idea of all the content that we would eventually have. I ve been toying with the idea in my mind and had some idea that we could add fun facts, postcards (an image with some text), time now in different timezones, Debian news (maybe procured by the press team), cards that contain the longer announcements that was sent to debconf-announce, perhaps a shout out or two and some photos from previous DebConfs like the group photos. I knew that I wouldn t be able to build anything substantial by the time DebConf starts, but adding content to OBS in between talks is relatively easy, so we could keep on building on it during DebConf.
Nattie provided the first shout out, and I made 2 video loops with the DC18/19 pictures and also two Did you know cards. So the flow I ended up with was: Sponsors -> Happening Now -> Random video (which would be any of those clips) -> Back to sponsors. This ended up working pretty well for quite a while. With the first batch of videos the sponsor loop would come up on average about every 2 minutes, but as much shorter clips like shout outs started to come in faster and faster, it made sense to play a few 2-3 shout-outs before going back to sponsors.
So here is a very brief guide on how I set up the sequencing in Advanced Scene Switcher.
If no condition was met, a video would play from the Random tab.
Then in the Random tab, I added the scenes that were part of the random mix. Annoyingly, you have to specify how long it should play for. If you don t, the no condition thingy is triggered and another video is selected. The time is also the length of the video minus one second, because
You can t just say that a random video should return back to a certain scene, you have to specify that in the sequence tab for each video. Why after 1 second? Because, at least in my early tests, and I didn t circle back to this, it seems like 0s can randomly either mean instantly, or never. Yes, this ended up being a bit confusing and tedious, and considering the late hours I worked on this, I m surprised that I didn t manage to screw it up completely at any point.
I also suspected that threads would eventually happen. That is, when people create video replies to other videos. We had 3 threads in total. There was a backups thread, beverage thread and an impersonation thread. The arrow in the screenshot above points to the backups thread. I know it doesn t look that complicated, but it was initially somewhat confusing to set up and make sense out of it.
For the next event, the Advanced Scene Switcher might just get some more taming, or even be replaced entirely. There are ways to drive OBS by API, and even the Advanced Scene Switcher tool can be driven externally to some degree, but I think we definitely want to replace it by the next full DebConf. We had the problem that when a talk ended, we would return to the loop in the middle of a clip, which felt very unnatural and sometimes even confusing. So Stefano helped me with a helper script that could read the socket from Vocto, which I used to write either Loop or Standby to a file, and then the scene switcher would watch that file and keep the sponsors loop ready for start while the talks play. Why not just switch to sponsors when the talk ends? Well, the little bit of delay in switching would mean that you would see a tiny bit of loop every time before switching to sponsors. This is also why we didn t have any loop for the ad-hoc track (that would have probably needed another OBS instance, we ll look more into solutions for this for the future).
Then for all the clips. There were over 50 of them. All of them edited by hand in kdenlive. I removed any hard clicks, tried to improve audibility, remove some sections at the beginning and the end that seemed extra and added some music that would reduce in volume when someone speaks. In the beginning, I had lots of fun with choosing music for the clips. Towards the end, I had to rush them through and just chose the same tune whether it made sense or not. For comparison of what a difference the music can make, compare the original and adapted version for Valhalla s clip above, or this original and adapted video from urbec. This part was a lot more fun than dealing with the video sequencer, but I also want to automate it a bit. When I can fully drive OBS from Python I ll likely instead want to show those cards and control music volume from Python (what could possibly go wrong ).
The loopy name happened when I requested an @debconf.org alias for this. I was initially just thinking about loop@debconf.org but since I wanted to make it clear that the purpose of this loop is also to have some fun, I opted for loopy instead:
I was really surprised by how people took to loopy. I hoped it would be good and that it would have somewhat positive feedback, but the positive feedback was just immense. The idea was that people typically saw it in between talks. But a few people told me they kept it playing after the last talk of the day to watch it in the background. Some asked for the music because they want to keep listening to it while working (and even for jogging!?). Some people also asked for recordings of the loop because they want to keep it for after DebConf. The shoutouts idea proved to be very popular. Overall, I m very glad that people enjoyed it and I think it s safe to say that loopy will be back for the next event.
Also throughout this experiment Loopy Loop turned into yet another DebConf mascot. We gain one about every DebConf, some by accident and some on purpose. This one was not quite on purpose. I meant to make an image for it for salsa, and started with an infinite loop symbol. That s a loop, but by just adding two more solid circles to it, it looks like googly eyes, now it s a proper loopy loop!
I like the progress we ve made on this, but there s still a long way to go, and the ideas keep heaping up. The next event is quite soon (MDCO#2 at the end of November, and it seems that 3 other MiniDebConf events may also be planned), but over the next few events there will likely be significantly better graphics/artwork, better sequencing, better flow and more layout options. I hope to gain some additional members in the team to deal with incoming requests during DebConf. It was quite hectic this time! The new OBS also has a scripting host that supports Python, so I should be able to do some nice things even within OBS without having to drive it externally (like, display a clock without starting a web browser).
The Loopy Loop Music
The two mini albums that mostly played during the first few days were just a copy and paste from the MDCO#1 music, which was:
I have much more things to say about DebConf20, but I ll keep that for another post, and hopefully we can get all the other video stuff in a post from the video team, because I think there s been some real good work done for this DebConf. Also thanks to Infomaniak who was not only a platinum sponsor for this DebConf, but they also provided us with plenty of computing power to run all the video stuff on. Thanks again!
Introducing cryptsetup-suspend
Today, we're introducing cryptsetup-suspend, whose job is to protect the content of your harddrives while the system is sleeping.
TL;DR:
For cryptsetup-suspend to work properly, at least Linux kernel 5.6 is required
We hope that in a bright future, everything will be available out-of-the-box in Debian and it's derivatives
Before:
After:
Table of contents
What does this mean and why should you care about it?
If you don't use full-disk encryption, don't read any further. Instead, think about, what will happen if you lose your notebook on the train, a random person picks it up and browses through all your personal pictures, e-mails, and tax records. Then encrypt your system and come back.
If you believe full-disk encryption is necessary, you might know that it only works when your machine is powered off. Once you turn on the machine and decrypt your harddrive, your encryption key stays in RAM and can potentially be extracted by malicious software or physical access. Even if these attacks are non-trivial, it's enough to worry about. If an attacker is able to extract your disk encryption keys from memory, they're able to read the content of your disk in return.
Sadly, in 2020, we hardly power off our laptops anymore. The sleep mode, also known as "suspend mode", is just too convenient. Just close the lid to freeze the system state and lift it anytime later in order to continue. Well, convenience usually comes with a cost: during suspend mode, your system memory is kept powered, all your data - including your encryption keys - stays there, waiting to be extracted by a malicious person. Unfortunately, there are practical attacks to extract the data of your powered memory.
Cryptsetup-suspend expands the protection of your full-disk encryption to all those times when your computer sleeps in suspend mode. Cryptsetup-suspend utilizes the suspend feature of LUKS volumes and integrates it with your Debian system. Encryption keys are evicted from memory before suspend mode and the volumes have to be re-opened after resuming - potentially prompting for the required passphrases.
By now, we have a working prototype which we want to introduce today. We did quite some testing, both on virtualized and bare-metal Debian and Ubuntu systems, with and without graphical stack, so we dare to unseal and set free the project and ask you - the community - to test, review, criticize and give feedback.
Here's a screencast of cryptsetup-suspend in action:
State of the implementation: where are we?
If you're interested in the technical details, here's how cryptsetup-suspend works internally. It basically consists of three parts:
cryptsetup-suspend: A C program that takes a list of LUKS devices as arguments, suspends them via luksSuspend and suspends the system afterwards. Also, it tries to reserve some memory for decryption, which we'll explain below.
cryptsetup-suspend-wrapper: A shell wrapper script which works the following way:
Extract the initramfs into a ramfs
Run (systemd) pre-suspend scripts, stop udev, freeze almost all cgroups
Chroot into the ramfs and run cryptsetup-suspend
Resume initramfs devices inside chroot after resume
Resume non-initramfs devices outside chroot
Thaw groups, start udev, run (systemd) post-suspend scripts
Unmount the ramfs
A systemd unit drop-in file overriding the Exec property of systemd-suspend.service so that it invokes the script cryptsetup-suspend-wrapper.
Reusing large parts of the existing cryptsetup-initramfs implementation has some positive side-effects: Out-of-the-box, we support all LUKS block device setups that have been supported by the Debian cryptsetup packages before.
Freezing most processes/cgroups is necessary to prevent possible race-conditions and dead-locks after the system resumes. Processes will try to access data on the locked/suspended block devices eventually leading to buffer overflows and data loss.
Technical challenges and caveats
Dead-locks at suspend: In order to prevent possible dead-locks between suspending the encrypted LUKS disks and suspending the system, we have to tell the Linux kernel to notsync() before going to sleep. A corresponding patch got accepted upstream in Linux 5.6. See section What about the kernel patch? below for details.
Race conditions at resume: Likewise, there's a risk of race conditions between resuming the system and unlocking the encypted LUKS disks. We went with freezing as many processes as possible as a counter measurement. See last part of section State of the implementation: where are we? for details.
Memory management: Memory management is definitely a challenge. Unlocking disks might require a lot of memory (if key derivation function is argon2i) and the swap device most likely is locked at that time. See section All that matters to me is the memories! below for details.
systemd dependency: Our implementation depends on systemd. It uses a unit drop-in file for systemd-suspend.service for hooking into the system suspend process and depends on systemds cgroup management to freeze and thaw processes. If you're using a different init system, sorry, you're currently out of luck.
What about the kernel patch?
The problem is simple: the Linux kernel suspend implementation enforces a final filesystem sync() before the system goes to sleep in order to prevent potential data loss. While that's sensible in most scenarios, it may result in dead-locks in our situation, since the block device that holds the filesystem is already suspended. The fssync() call will block forever as it waits for the block device to finish the sync() operation. So we need a way to conditionally disable this sync() call in the Linux kernel resume function. That's what our patch does, by introducing a run-time switch at /sys/power/sync_on_suspend, but it only got accepted into the Linux kernel recently and was first released with Linux kernel 5.6.
Since release 4.3, the Linux kernel at least provides a build-time flag to disable the sync(): CONFIG_SUSPEND_SKIP_SYNC (that was called SUSPEND_SKIP_SYNC first and renamed to CONFIG_SUSPEND_SKIP_SYNC in kernel release 4.9). Enabling this flag at build-time protects you against the dead locks perfectly well. But while that works on an individual basis, it's a non-option for the distribution Linux kernel defaults. In most cases you still want the sync() to happen, except if you have user-space code that takes care of the sync() just before suspending your system - just like our cryptsetup-suspend implementation does.
So in order to properly test cryptsetup-suspend, you're strongly advised to run Linux kernel 5.6 or newer. Fortunately, Linux 5.6 is available in buster-backports thanks to the Debian Kernel Team.
All that matters to me is the memories!
One of the tricky parts is memory management. Since version 2, LUKS uses argon2i as default key derivation function. Argon2i is a memory-hard hash function and LUKS2 assigns the minimum of half of your systems memory or 1 GB to unlocking your device. While this is usually unproblematic during system boot - there's not much in the system memory anyway - it can become problematic when suspending. When cryptsetup tries to unlock a device and wants 1 GB of memory for this, but everything is already occupied by your browser and video player, there's only two options what to do:
Kill a process to free some memory
Move some of the data from memory to swap space
The first option is certainly not what you expect when suspending your system. The second option is impossible, because swap is located on your harddrive which we have locked before. Our current solution is to allocate the memory after freezing the other processes, but before locking the disks. At this time, the system can still move data to swap, but it won't be accessed anymore. We then release the memory just in time for cryptsetup to claim it again. The implementation of this is still subject to change.
What's missing: A proper user interface
As mentioned before, we consider cryptsetup-suspend usable, but it certainly still has bugs and shortcomings. The most obvious one is lack of a proper user interface. Currently, we switch over to a tty command-line interface to prompt for passphrases when unlocking the LUKS devices. It certainly would be better to replace this with a graphical user interface later, probably by using plymouth or something alike. Unfortunately, it seems rather impossible to spawn a real graphical environment for the passphrase prompt. That would imply to load the full graphical stack into the ramfs, raising the required amount of memory significantly. Lack of memory is currently our biggest concern and source of trouble.
We'd definitely appreciate to learn about your ideas how to improve the user experience here.
Let's get practical: how to use
TL;DR: On Debian Bullseye (Testing), all you need to do is to install the cryptsetup-suspend package from experimental. It's not necessary to upgrade the other cryptsetup packages. On Debian Buster, cryptsetup packages from backports are required.
First, be sure that you're running Linux kernel 5.6 or newer. For Buster systems, it's available in buster-backports.
Third, install the cryptsetup-suspend package from experimental. Beware that cryptsetup-suspend depends on cryptsetup-initramfs (>= 2:2.3.3-1~). Either you need the cryptsetup packages from testing/unstable, or the backports from buster-backports.
Now that you have the cryptsetup-suspend package installed, everything should be in place: Just send your system to sleep. It should switch to a virtual text terminal before going to sleep, ask for a passphrase to unlock your encrypted disk(s) after resume and switch back to your former working environment (most likely your graphical desktop environment) afterwards.
Security considerations
Suspending LUKS devices basically means to remove the corresponding encryption keys from system memory. This protects against all sort of attacks trying to read them from there, e.g. cold-boot attacks. But, cryptsetup-suspend only protects the encryption keys of your LUKS devices. Most likely there's more sensitive data in system memory, like all kinds of private keys (e.g. OpenPGP, OpenSSH) or documents with sensitive content.
We hope that the community will help improve this situation by providing useful pre-/post-suspend scripts. A positive example is KeepassXC, which is able to lock itself when going to suspend mode.
Related and similar projects
Systemd Homed: systemd recently got a new feature to manage home directories. It brings support for encrypting your home directory within a LUKS2 container and for suspending the LUKS2 container during system sleep. It all is limited to systemd home directories though and doesn't help with other LUKS devices.
There's several earlier luks-suspend-* implementations. Unfortunately, neither of them deal with all the Technical challenges and caveats we discovered. Still we'd like to mention some of them:
Feedback and Comments
We'd be more than happy to learn about your thoughts on cryptsetup-suspend. For specific issues, don't hesitate to open a bugreport against cryptsetup-suspend. You can also reach us via mail - see the next section for contact addresses. Last but not least, comments below the blogpost work as well.
rejected
autotalent (not the package),
bart (logo),
mumble-server (client UI),
hpcc (not a screenshot)
approved deletion of
theli (replacing incorrect screenshot)
rejected deletion of
gnome-bluetooth/aptitude/torbrowser-launcher (unintelligible),
phpbb3/hashcat/onboard/kcharselect (spam),
various packages (not the place to report abuse),
vim (not the place to send kudos)
Administration
Debian wiki:
unblock IP addresses,
approve accounts,
reset email addresses
This post was originally published in the Wikimedia Tech blog, and
is authored by Arturo Borrero Gonzalez and Brooke Storm.
In the previous post, we shared the context on the recent Kubernetes upgrade that we
introduced in the Toolforge service. Today we would like to dive a bit more in the technical
details.
Custom admission controllers
One of the key components of the Toolforge Kubernetes are our custom admission controllers. We use
them to validate and enforce that the usage of the service is what we intended for. Basically, we
have 2 of them:
The source code is written in Golang, which is pretty convenient for natively working in a
Kubernetes environment. Both code repositories include extensive documentation: how to develop,
test, use, and deploy them. We decided to go with custom admission controllers because we couldn t
find any native (or built-in) Kubernetes mechanism to accomplish the same sort of checks on user
activity.
With the Ingress controller, we want to ensure that Ingress objects only handle traffic to our
internal domains, which by the time of this writing, are toolforge.org
(our new domain) and tools.wmflabs.org (legacy). We safe-list the kube-system
namespace and the tool-fourohfour namespace because both need special consideration. More on the
Ingress setup later.
The registry controller is pretty simple as well. It ensures that only our
internal docker registry is used for user-scheduled containers running in Kubernetes.
Again, we exclude from the checks containers running in the kube-system namespace (those used by
Kubernetes itself). Other than that, the validation itself is pretty easy. For some extra
containers we run (like those related to Prometheus metrics) what we do is simply upload those
docker images to our internal registry. The controls provided by this admission controller helps us
validate that only FLOSS software is run in our environment, which is
one of the core rules of Toolforge.
RBAC and Pod Security Policy setup
I would like to comment next on our RBAC and Pod Security Policy setup. Using the Pod
Security Policies (or PSP) we establish a set of constraints on what containers can and can t do in
our cluster. We have many PSP configured in our setup:
Privileged policy: used by Kubernetes containers themselves basically a very relaxed set of
constraints that are required for the system itself to work.
Default policy: a bit more restricted than the privileged policy, is intended for admins to
deploy services, but it isn t currently in use..
Toolforge user policies: this applies to user-scheduled containers, and there are some obvious
restrictions here: we only allow unprivileged pods, we control which HostPath is available for
pods, use only default Linux capabilities, etc.
Each user can interact with their own namespace (this is how we achieve multi-tenancy in the
cluster). Kubernetes knows about each user by means of TLS certs, and for that we have RBAC. Each
user has a rolebinding to a shared cluster-role that defines how Toolforge tools can use the
Kubernetes API. The following diagram shows the design of our RBAC and PSP in our cluster:
RBAC and PSP for Toolforge, original image in wikitech
I mentioned that we know about each user by means of TLS certificates. This is true, and in fact,
there is a key component in our setup called maintain-kubeusers. This custom piece
of Python software is run as a pod inside the cluster and is responsible for reading our external
user database (LDAP) and generating the required credentials, namespaces, and other configuration
bits for them. With the TLS cert, we basically create a kubeconfig file that is then written into
the homes NFS share, so each Toolforge user has it in their shell home directory.
Networking and Ingress setup
With the basic security controls in place, we can move on to explaining our networking and Ingress
setup. Yes, the Ingress word might be a bit overloaded already, but we refer here to
Ingress as the path that end-users follow from their web browser in their local machine to a
webservice running in the Toolforge cluster.
Some additional context here. Toolforge is not only Kubernetes, but we also have a Son of
GridEngine deployment, a job scheduler that covers some features not available in Kubernetes. The
grid can also run webservices, although we are encouraging users to migrate them to Kubernetes. For
compatibility reasons, we needed to adapt our Ingress setup to accommodate the old web grid.
Deciding the layout of the network and Ingress was definitely something that took us some time to
figure out because there is not a single way to do it right.
The following diagram can be used to explain the different steps involved in serving a web service
running in the new Toolforge Kubernetes.
Toolforge k8s network topology, original image in Wikitech
The end-user HTTP/HTTPs request first hits our front proxy in (1). Running here is
NGINX with a custom piece of LUA code that is able to decide whether to contact the web grid
or the new Kubernetes cluster. TLS termination happens here as well, for both domains
(toolforge.org and tools.wmflabs.org). Note this proxy is reachable from the internet, as it
uses a public IPv4 address, a floating IP from CloudVPS, the infrastructure service we
provide based on Openstack. Remember that our Kubernetes is directly built in virtual machines a
bare-metal type deployment.
If the request is directed to a webservice running in Kubernetes, the request now reaches
haproxy in (2), which knows the cluster nodes that are available for Ingress. The
original 80/TCP packet is now translated to 30000/TCP; this is the TCP port we use internally for
the Ingress traffic. This haproxy instance provides load-balancing also for the Kubernetes API as
well, using 6443/TCP. It s worth mentioning that unlike the Ingress, the API is only reachable from
within the cluster and not from the internet.
We have a NGINX-Ingress NodePort service listening in 30000/TCP in every Kubernetes worker node in
(3); this helps the request to eventually reach the actual NGINX-Ingress pod in (4), which is
listening in 8080/TCP. You can see in the diagram how in the API server (5) we hook the Ingress
admission controller (6) to validate Kubernetes Ingress configuration objects before allowing them
in for processing by NGINX-Ingress (7).
The NGINX-Ingress process knows which tools webservices are online and how to contact them by means
of an intermediate Service object in (8). This last Service object means the request finally
reaches the actual tool pod in (9). At this point, it is worth noting that our Kubernetes cluster
uses internally kube-proxy and Calico, both using Netfilter components to handle traffic.
tools-webservice
Most user-facing operations are simplified by means of another custom piece of Python code:
tools-webservice. This package provides users with the webservice command line
utility in our shell bastion hosts. Typical usage is to just run webservice start stop status. This
utility creates all the required Kubernetes objects on-demand like Deployment, ReplicaSet, Ingress
and Service to ease deploying web apps in Toolforge. Of course, advanced users can interact
directly with Kubernetes API and create their custom configuration objects. This utility is just a
wrapper, a shortcut.
tool-fourohfour and tool-k8s-status
The last couple of custom components we would like to mention are the tool-fourohfour
and tool-k8s-status web services. These two utilities run inside the cluster as if
they were any other user-created tool. The fourohfour tool allows for a controlled handling of HTTP
404 errors, and it works as the default NGINX-Ingress backend. The k8s-status tool shows plenty of
information about the cluster itself and each tool running in the cluster, including links to the
Server Admin Log, an auto-generated grafana dashboard for metrics, and more.
For metrics, we use an external Prometheus server that contacts the Kubernetes cluster to scrape
metrics. We created a custom metrics namespace in which we deploy all the different
components we use to observe the behavior of the system:
metrics-server: used by some utilities like kubectl top.
kube-state-metrics: provides advanced metrics about the state of the cluster.
cadvisor: to obtain fine-grained metrics about pods, deployments, nodes, etc.
All the Prometheus data we collect is used in several different Grafana dashboards, some of them
directed for user information like the ones linked by the k8s-status tool and some others for
internal use by us the engineers. These are for internal use but are still public, like the
Ingress specific dashboard, or the cluster state dashboard. Working
publicly, in a transparent way, is key for the success of CloudVPS in general and Toolforge in
particular. Like we commented in the previous post, all the engineering work that was done here was
shared by community members.
By the community, for the community
We think this post sheds some light on how the Toolforge Kubernetes service works, and we hope it
could inspire others when trying to build similar services or, even better, help us improve
Toolforge itself. Since this was first put into production some months ago we detected already some
margin for improvement in a couple of the components. As in many other engineering products, we
will follow an iterative approach for evolving the service. Mind that Toolforge is maintained by
the Wikimedia Foundation, but you can think of it as a service by the community for the community.
We will keep an eye on it and
have a list of feature requests and things to improve in the future. We are looking forward
to it!
This post was originally published in the Wikimedia Tech blog, and
is authored by Arturo Borrero Gonzalez and Brooke Storm.
Sporting a beautiful 10.1 1920x1200 display, the Lenovo IdeaPad Duet
Chromebook or Duet Chromebook, is one of the latest Chromebooks released,
and one of the few slate-style tablets, and it s only about 300 EUR (300 USD).
I ve had one for about 2 weeks now, and here are my thoughts.
Build & Accessories
The tablet is a fairly Pixel-style affair, in that the back has two components,
one softer blue one housing the camera and a metal feeling gray one. Build quality
is fairly good.
The volume and power buttons are located on the right side of the tablet, and
this is one of the main issues: You end up accidentally pressing the power button
when you want to turn your volume lower, despite the power button having a different
texture.
Alongside the tablet, you also find a kickstand with a textile back, and a
keyboard, both of which attach via magnets (and pogo pins for the keyboard).
The keyboard is crammed, with punctuation keys being halfed in size, and it
feels mushed compared to my usual experiences of ThinkPads and Model Ms, but
it s on par with other Chromebooks, which is surprising, given it s a tablet
attachment.
fully assembled chromebook duet
I mostly use the Duet as a tablet, and only attach the keyboard occasionally.
Typing with the keyboard on your lap is suboptimal.
My first Duet had a few bunches of dead pixels, so I returned it, as I had
a second one I could not cancel ordered as well. Oh dear. That one was fine!
Hardware & Connectivity
The Chromebook Duet is powered by a Mediatek Helio P60T SoC, 4GB of RAM,
and a choice of 64 or 128 GB of main storage.
The tablet provides one USB-C port for charging, audio output (a 3.5mm adapter
is provided in the box), USB hub, and video output; though, sadly, the latter
is restricted to a maximum of 1080p30, or 1440x900 at 60 Hz. It can be charged
using the included 10W charger, or use up to I believe 18W from a higher powered
USB-C PD charger. I ve successfully used the Chromebook with a USB-C monitor
with attached keyboard, mouse, and DAC without any issues.
On the wireless side, the tablet provides 2x2 Wifi AC and Bluetooth 4.2. WiFi
reception seemed just fine, though I have not done any speed testing, missing
a sensible connection at the moment. I used Bluetooth to connect to my smartphone
for instant tethering, and my Sony WH1000XM2 headphones, both of which worked
without any issues.
The screen is a bright 400 nit display with excellent viewing angles,
and the speakers do a decent job, meaning you can use easily use this
for watching a movie when you re alone in a room and idling around. It has
a resolution of 1920x1200.
The device supports styluses following the USI standard. As of right now, the
only such stylus I know about is an HP one, and it costs about 70 or so.
Cameras are provided on the front and the rear, but produce terrible images.
Software: The tablet experience
The Chromebook Duet runs Chrome OS, and comes with access to Android apps
using the play store (and sideloading in dev mode) and access to full Linux
environments powered by LXD inside VMs.
The screen which has 1920x1200 is scaled to a ridiculous 1080x675 by default
which is good for being able to tap buttons and stuff, but provides next to no
content. Scaling it to 1350x844 makes things more balanced.
The Linux integration is buggy. Touches register in different places than where
they happened, and the screen is cut off in full screen extremetuxracer, making
it hard to recommend for such uses.
Android apps generally work fine. There are some issues with the back gesture
not registering, but otherwise I have not found issues I can remember.
One major drawback as a portable media consumption device is that Android apps
only work in Widevine level 3, and hence do not have access to HD content, and
the web apps of Netflix and co do not support downloading. Though one of the Duets
actually said L1 in check apps at some point (reported in issue 1090330).
It s also worth
noting that Amazon Prime Video only renders in HD, unless you change your
user agent to say you are Chrome on Windows - bad Amazon!
The tablet experience also lags in some other ways, as the palm rejection is
overly extreme, causing it to reject valid clicks close to the edge of the display
(reported in issue 1090326).
The on screen keyboard is terrible. It only does one language at a time, forcing
me to switch between German and English all the time, and does not behave as you d
expect it when editing existing words - it does not know about them and thinks
you are starting a new one. It does provide a small keyboard that you can
move around, as well as a draw your letters keyboard, which could come in
handy for stylus users, I guess. In any case, it s miles away from gboard on
Android.
Stability is a mixed bag right now. As of Chrome OS 83, sites (well only Disney+
so far ) sometimes get killed with SIGILL or SIGTRAP, and the device rebooted
on its own once or twice. Android apps that use the DRM sometimes do not start,
and the Netflix Android app sometimes reports it cannot connect to the servers.
Performance
Performance is decent to sluggish, with micro stuttering in a lot of places. The
Mediatek CPU is comparable to Intel Atoms, and with only 4GB of RAM, and an entire
Android container running, it s starting to show how weak it is.
I found that Google Docs worked perfectly fine, as did websites such as
Mastodon, Twitter, Facebook. Where the device really struggled was Reddit,
where closing or opening a post, or getting a reply box could take 5 seconds
or more. If you are looking for a Reddit browsing device, this is not for you.
Performance in Netflix was fine, and Disney+ was fairly slow but still usable.
All in all, it s acceptable, and given the price point and the build quality,
probably the compromise you d expect.
Summary
tl;dr:
good: Build quality, bright screen, low price, included accessories
The Chromebook Duet or IdeaPad Duet Chromebook is a decent tablet that is built
well above its price point. It s lackluster performance and DRM woes make it
hard to give a general recommendation, though. It s not a good laptop.
I can see this as the perfect note taking device for students, and as a
cheap tablet for couch surfing, or as your on-the-go laptop replacement,
if you need it only occasionally.
I cannot see anyone using this as their main laptop, although I guess some
people only have phones these days, so: what do I know?
I can see you getting this device if you want to tinker with Linux on ARM, as
Chromebooks are quite nice to tinker with, and a tablet is super nice.
This post was originally published in the Wikimedia Tech blog, and
is authored by Arturo Borrero Gonzalez and Brooke Storm.
One of the most successful and important products provided by the Wikimedia
Cloud Services team at the Wikimedia Foundation is
Toolforge. Toolforge is a platform that allows users and
developers to run and use a variety of applications that help the Wikimedia
movement and mission from the technical point of view in general. Toolforge is
a hosting service commonly known in the industry as a Platform as a Service
(PaaS). Toolforge is powered by two different backend engines,
Kubernetes and GridEngine.
This article focuses on how we made a better Toolforge by integrating a newer
version of Kubernetes and, along with it, some more modern workflows.
The starting point in this story is 2018. Yes, two years ago! We identified
that we could do better with our Kubernetes deployment in Toolforge. We were
using a very old version, v1.4. Using an old version of any software has more
or less the same consequences everywhere: you lack security improvements and
some modern key features.
Once it was clear that we wanted to upgrade our Kubernetes cluster, both the
engineering work and the endless chain of challenges started.
It turns out that Kubernetes is a complex and modern technology, which adds
some extra abstraction layers to add flexibility and some intelligence to a
very old systems engineering need: hosting and running a variety of
applications.
Our first challenge was to understand what our use case for a modern Kubernetes
was. We were particularly interested in some key features:
The increased security and controls required for a public user-facing
service, using RBAC, PodSecurityPolicies, quotas, etc.
Native multi-tenancy support, using namespaces
Advanced web routing, using the Ingress API
Soon enough we faced another Kubernetes native challenge: the documentation.
For a newcomer, learning and understanding how to adapt Kubernetes to a given
use case can be really challenging. We identified some baffling patterns in the
docs. For example, different documentation pages would assume you were using
different Kubernetes deployments (Minikube vs kubeadm vs a hosted service). We
are running Kubernetes like you would on bare-metal (well, in
CloudVPS virtual machines), and some documents directly referred to
ours as a corner case.
During late 2018 and early 2019, we started brainstorming and prototyping. We
wanted our cluster to be reproducible and easily rebuildable, and in the
Technology Department at the Wikimedia Foundation, we rely on Puppet
for that.
One of the first things to decide was how to deploy and build the cluster while
integrating with Puppet. This is not as simple as it seems because Kubernetes
itself is a collection of reconciliation loops, just like Puppet is. So we had
to decide what to put directly in Kubernetes and what to control and make
visible through Puppet. We decided to stick with kubeadm as the deployment
method, as it seems to be the more upstream-standardized tool for the task. We
had to make some interesting decisions by trial and error, like where to run
the required etcd servers, what the kubeadm init file would look like, how to
proxy and load-balance the API on our bare-metal deployment, what network
overlay to choose, etc. If you take a look at our public notes, you
can get a glimpse of the number of decisions we had to make.
Our Kubernetes wasn t going to be a generic cluster, we needed a Toolforge
Kubernetes service. This means we don t use some of the components, and also,
we add some additional pieces and configurations to it. By the second half of
2019, we were working full-speed on the new Kubernetes cluster. We already had
an idea of what we wanted and how to do it.
There were a couple of important topics for discussions, for example:
Ingress
Validating admission controllers
Security policies and quotas
PKI and user management
We will describe in detail the final state of those pieces in another blog
post, but each of the topics required several hours of engineering time,
research, tests, and meetings before reaching a point in which we were
comfortable with moving forward.
By the end of 2019 and early 2020, we felt like all the pieces were in place,
and we started thinking about how to migrate the users, the workloads, from the
old cluster to the new one. This migration plan mostly materialized in a
Wikitech page which contains concrete information for our users
and the community.
The interaction with the community was a key success element. Thanks to our
vibrant and involved users, we had several early adopters and beta testers that
helped us identify early flaws in our designs. The feedback they provided was
very valuable for us. Some folks helped solve technical problems, helped with
the migration plan or even helped make some design decisions. Worth noting that
some of the changes that were presented to our users were not easy to handle
for them, like new quotas and usage limits. Introducing new workflows and
deprecating old ones is always a risky operation.
Even though the migration procedure from the old cluster to the new one was
fairly simple, there were some rough edges. We helped our users navigate them.
A common issue was a webservice not being able to run in the new cluster due
to stricter quota limiting the resources for the tool. Another example
is the new Ingress layer failing to properly work with some webservices s
particular options.
By March 2020, we no longer had anything running in the old Kubernetes cluster,
and the migration was completed. We then started thinking about another step
towards making a better Toolforge, which is introducing the toolforge.org
domain. There is plenty of information about the change to this new domain in
Wikitech News.
The community wanted a better Toolforge, and so do we, and after almost 2 years
of work, we have it! All the work that was done represents the commitment of
the Wikimedia Foundation to support the technical community and how we really
want to pursue technical engagement in general in the Wikimedia movement. In a
follow-up post we will present and discuss more in-depth about some technical
details of the new Kubernetes cluster, stay tuned!
This post was originally published in the Wikimedia Tech blog, and
is authored by Arturo Borrero Gonzalez and Brooke Storm.
 Ten years ago
Ten years ago 
 Zeeshan of IYC (India Youth Congress) along with Salman Khan s non-profit Being Human getting oxygenators
Zeeshan of IYC (India Youth Congress) along with Salman Khan s non-profit Being Human getting oxygenators 






 Prerequisites
You will need the following prerequisites :
Prerequisites
You will need the following prerequisites :
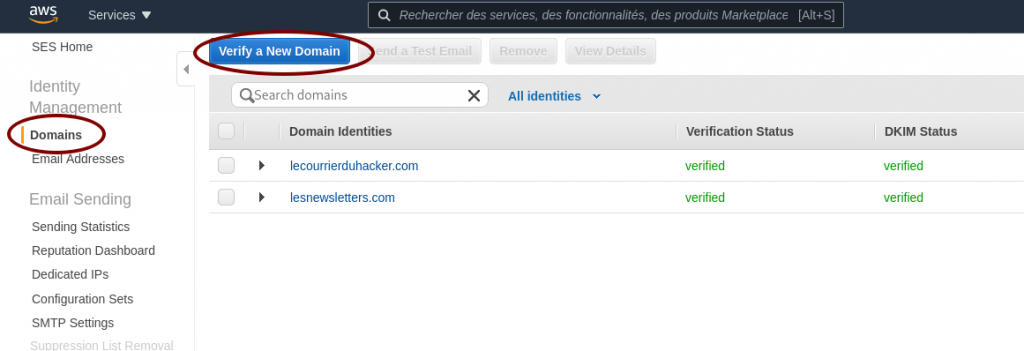 Ask AWS SES to verify a domain
Ask AWS SES to verify a domain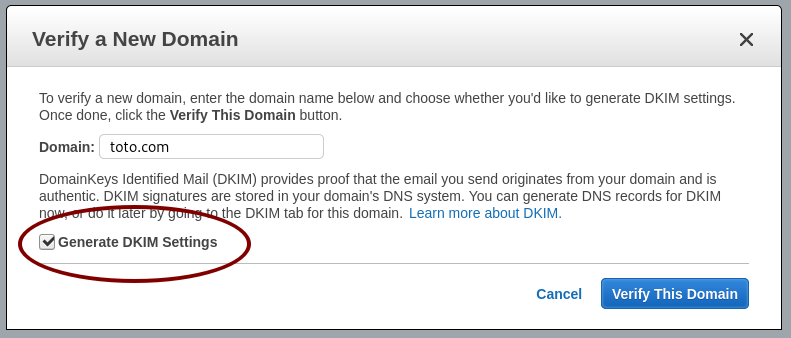 Generate the DKIM settings
Generate the DKIM settings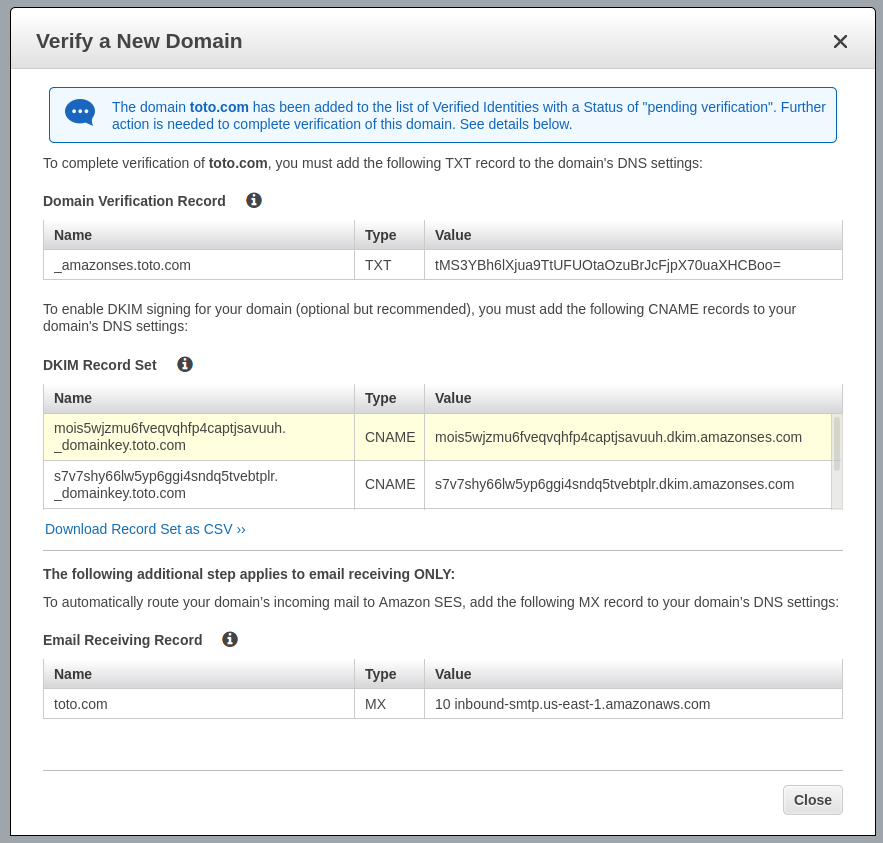
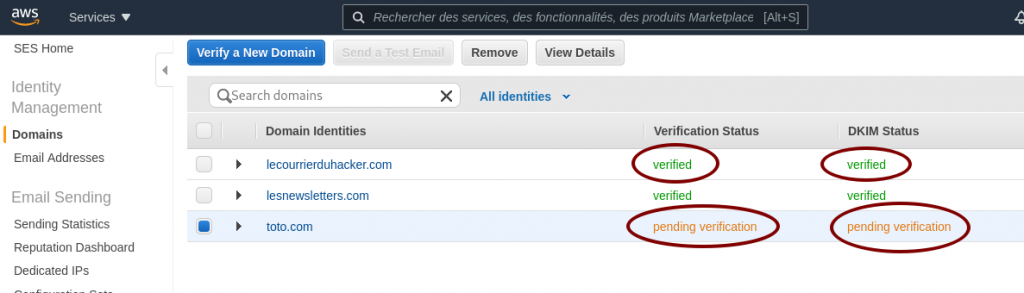 AWS SES pending verification
AWS SES pending verification AWS SES SMTP settings and credentials
AWS SES SMTP settings and credentials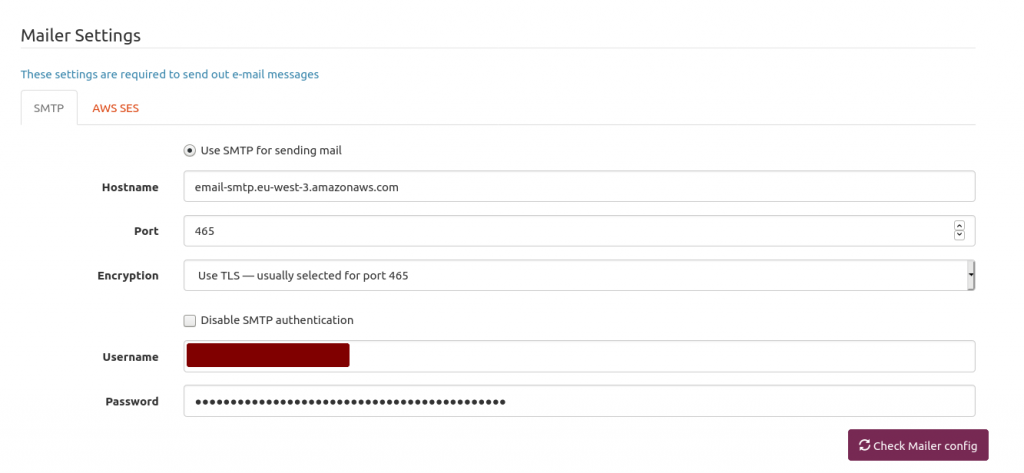 Mailtrain mailer setup
Mailtrain mailer setup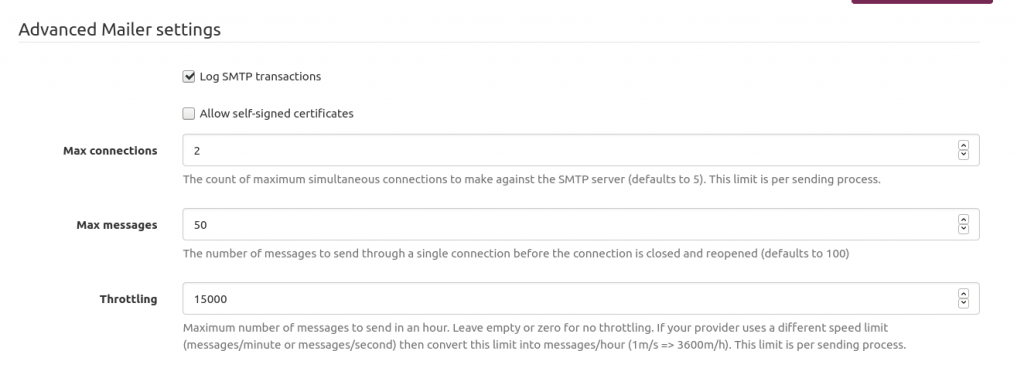 Mailtrain to throttle sending emails to AWS SES
Mailtrain to throttle sending emails to AWS SES



 I grew up riding bikes with my friends, but I didn't keep it up once I went to
University. A couple of my friends persevered and are really good riders, even
building careers on their love of riding.
I bought a mountain bike in 2006 (a sort of "first pay cheque" treat after
changing roles) but didn't really ride it all that often until this year. Once
Lockdown began, I started going for early morning rides in order to get some
fresh air and exercise.
Once I'd got into doing that I decided it was finally time to buy a new bike.
I knew I wanted something more like a "hybrid" than a mountain bike but apart
from that I was clueless. I couldn't even name the top manufacturers.
I grew up riding bikes with my friends, but I didn't keep it up once I went to
University. A couple of my friends persevered and are really good riders, even
building careers on their love of riding.
I bought a mountain bike in 2006 (a sort of "first pay cheque" treat after
changing roles) but didn't really ride it all that often until this year. Once
Lockdown began, I started going for early morning rides in order to get some
fresh air and exercise.
Once I'd got into doing that I decided it was finally time to buy a new bike.
I knew I wanted something more like a "hybrid" than a mountain bike but apart
from that I was clueless. I couldn't even name the top manufacturers.




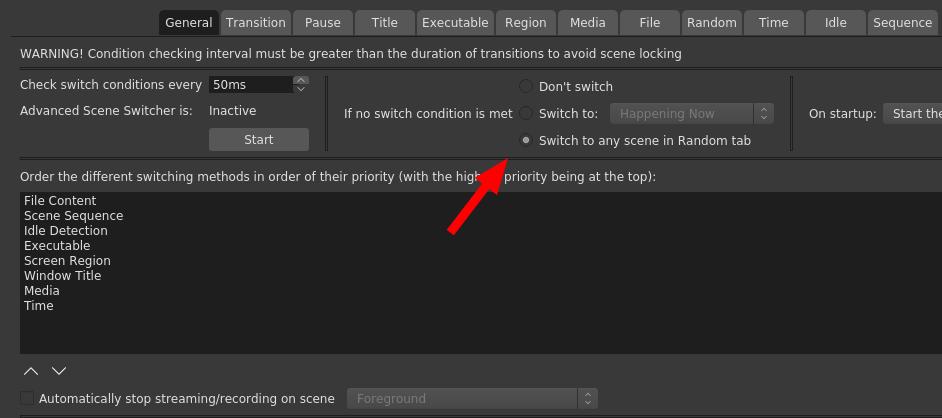
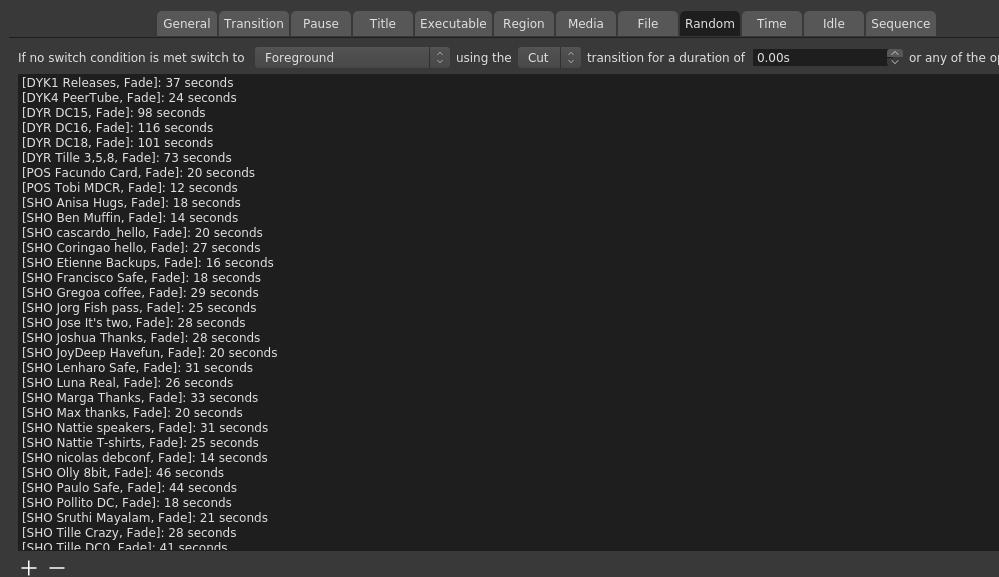
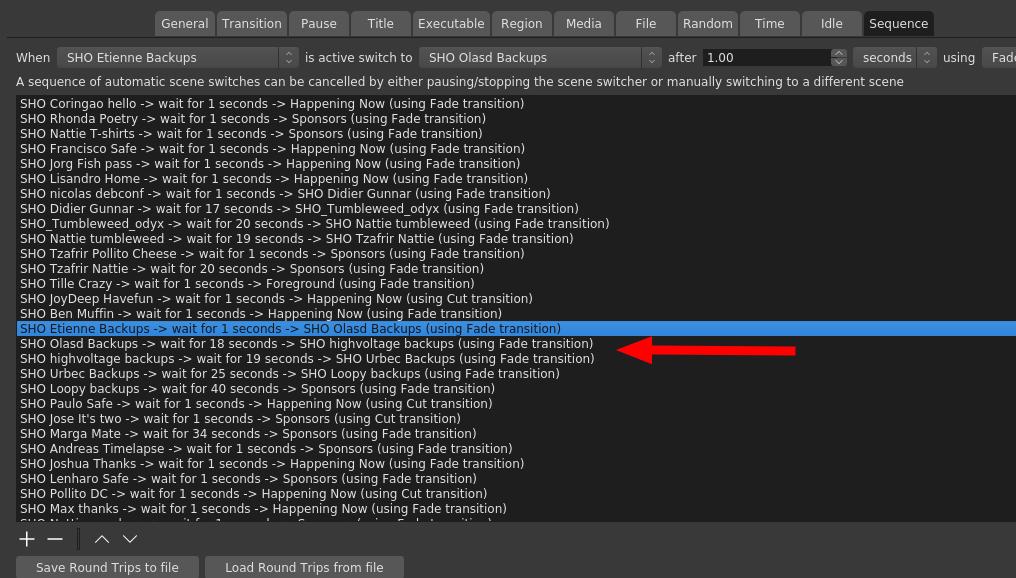
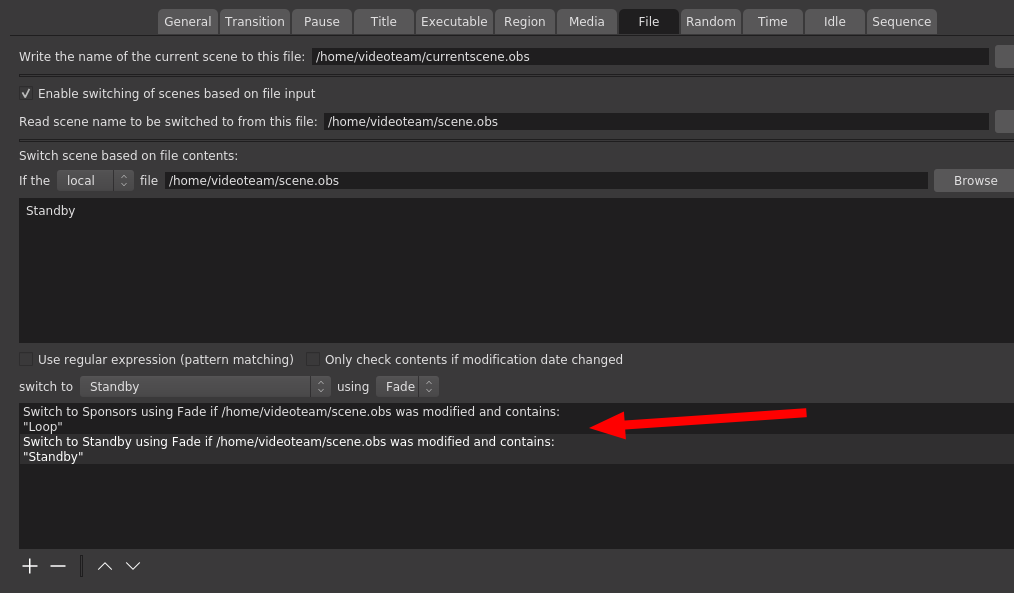

 After:
After:



 This post was originally published in the
This post was originally published in the 
 fully assembled chromebook duet
fully assembled chromebook duet
{kind=link}
{kind=link}